Scaling blockchains is not an easy task. Less so if one is looking to accommodate not only crypto-native use cases but also Web 2.0-like applications handling significant volumes of data at high throughput (of the kind that you would host with your preferred cloud provider).
One of the main culprits of blockchains' inability to scale well is their consensus layer. For the most part, consensus algorithms deployed in production can only order and validate transactions sequentially, limiting the system’s overall throughput. Even those proposed algorithms that are able to parallelise transaction processing hit a limit when facing large-scale networks or high-throughput and low-latency applications1.
To overcome these limitations, many projects are exploring how to scale blockchains horizontally and parallelise transaction validation and execution. This has been an active line of research at ConsensusLab since its creation. Today, we are thrilled to share a first iteration of the Filecoin hierarchical consensus framework. This tool will allow users to scale Filecoin horizontally to accommodate the needs of diverse applications.
Roughly speaking, we can divide the approaches being explored to horizontally scale blockchains into two broad categories: sharding and sidechains. In sharding, the state of the network is split into different partitions, known as shards (originally from database architecture), each shard validating its own transactions in parallel. The main complexity of sharded blockchains lies in handling transactions that affect the state stored in several shards. In sidechain approaches, a new, independent blockchain is spawned to process transactions. This sidechain usually has some fast consensus (or no consensus at all), coupled with a protocol to commit or checkpoint transactions into the original blockchain periodically. This is the case, for instance, for many Layer-2 projects.
At ConsensusLab, we do not think there is a one-size-fits-all solution to horizontally scaling blockchains. There is always a trade-off between security and scalability, and we cannot realistically predict the right balance for every possible use case. With hierarchical consensus, we want to give developers the tools to choose the approach that best meets the needs of their applications, building upon all the research done around sharding and sidechains.
Are you a demo-first kind of reader? Then watch our prototype implementation in action!
A brief introduction to hierarchical consensus
Hierarchical consensus is a framework to enable on-demand horizontal scalability of Filecoin (and potentially other blockchain networks) by spawning new subnetworks, each running their own consensus algorithm and keeping their state tree, while maintaining the ability to interact with any other subnet in the hierarchy seamlessly.
With hierarchical consensus, users in the Filecoin network (the root of the hierarchy) can spawn new subnets running the consensus algorithm that better suits the needs of their applications. Subnets are required to register to the hierarchy to interact with other subnets in the system. Each subnet may enforce its own policies and requirements for new users and miners to join. You can think of hierarchical consensus subnets as sidechains validating transactions in parallel but with the ability to execute transactions across subnets.
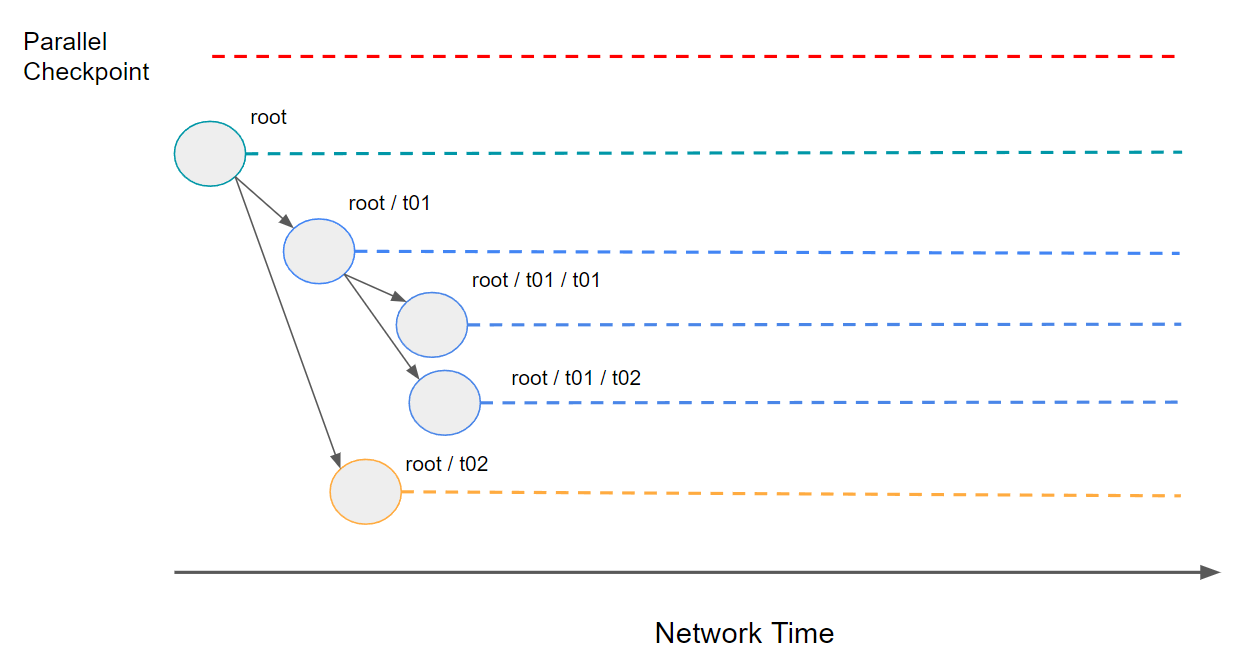
The evolution of the consensus hierarchy.
New subnets do not need to be spawned from the root chain; they may be spawned from any subnet in the hierarchy (in other words: from any point in the tree). As developers need to scale their applications further, they can spawn new subnets from the subnet they are currently operating, naturally building the hierarchy of networks in the system.
We don’t enforce security requirements in subnets; instead, users can deploy subnets with any policy they want and the corresponding security guarantees. However, to protect attacks on subnets from impacting the upper layers of the hierarchy, we enforce a firewall requirement in every subnet. Hence, the impact an attack on a subnet can have over its parent and the upper layers of the hierarchy is limited. In the current reference implementation of the protocol, the impact is limited by the circulating token supply injected by users into the subnet.
Subnets implement a checkpointing protocol to periodically commit to their parent proofs of the state of their chain in order to leverage the security of the upper layers of the hierarchy. Additionally, these checkpoints are also used to propagate cross-net transactions to other subnets in the system.
But how are all these interactions between the different subnets in the hierarchy orchestrated? Every subnet instantiates a built-in system actor that we call the Subnet Coordinator Actor (SCA), which implements all the logic required by the framework and serves as the gateway to the rest of the network. The governance of every subnet in the hierarchy is implemented and enforced by a Subnet Actor (SA). This actor is user-defined, and we only require that it implement the proper interface.
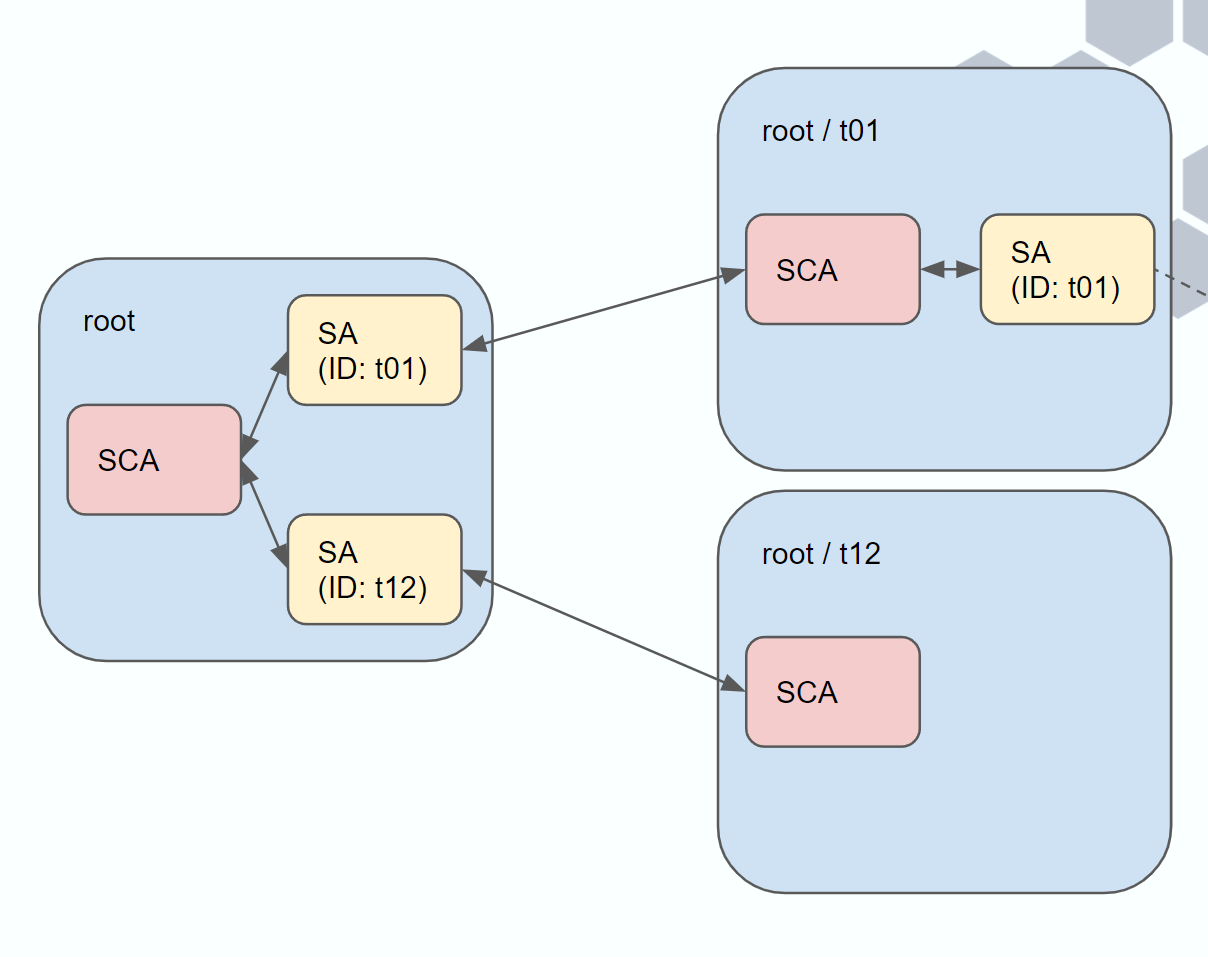
Actor interactions.
Read the spec and stay up to date!
This is but a brief overview of hierarchical consensus, the rationale behind the proposal, and a glimpse of the potential it may unlock. There is much more on hierarchical consensus out there.
We invite you to watch our recent Protocol Labs Research Seminar, which goes into more detail than we could in this text:
Then, if you want to go deep on how the system works or would like to take our reference implementation of the protocol for a spin, you might proceed to:
- Read our living spec
- Read the code and contribute
- Follow our roadmap
- And join our discussions by contributing your ideas, thoughts, or feedback
We will continue to expand on this subject, so check the blog for new posts!
ConsensusLab has a home in #consensus in the Filecoin Slack. If you want to know more about our work and day-to-day, follow the link and join us for a chat. And if you’d like to work with us, we’re looking for Research Engineers and Research Scientists.
Footnotes
-
It’s worth noting that not all transactions can be parallelised and some need to be executed sequentially. However, a large enough fraction of them can, and that’s enough to increase system capacity substantially. ↩︎