This is a design report – a story about the tradeoffs and challenges that we encountered while building a medium-complexity React component in TypeScript. These include
- state modeling (“making illegal states unrepresentable”)
- basic type-level programming in TypeScript
- DX patterns for generically typed React components
- DX patterns for reusable controlled components using a Redux-like action/dispatch state paradigm
These topics all deal with the external interface and TypeScript typings; lower-level implementation challenges (like optimizing drag interactions and sharing state between React and D3) have been left to a future post.
If you’re already a TypeScript expert, then you probably won’t find anything novel in here. But if you haven’t seen more advanced features like generics applied to practical web development, then this is for you!
Table of Contents
Background
Dataflow editors are a broad class of drag-and-drop-oriented interactive block diagram interfaces. You’ve probably seem them before:
Dataflow editors are useful for creating graphs of connections that might be too complex to fit in a traditional hierarchical interface. Plus, they encourage the user to visualize their data (or whatever the editor is used for) “flowing” through the edges by rendering them as explicit, reified things, instead of just implying relationships through nesting and positioning.
Dataflow interfaces aren’t particularly common to find in the wild, but they are dominant in some niches, like VFX software. Some other prominent examples include
- Max/MSP, a live music and multimedia programming environment (and its open-source analog Pure Data)
- Antimony, “CAD from a parallel universe”
- Enso (formerly Luna), a general-purpose visual programming language
- LabVIEW, a proprietary “system-design platform and development environment”
The sheer complexity of dataflow interfaces can be off-putting, but they’ve found their place in plenty of applications that aren’t well-served by more standard UIs.
Motivation
There are also several browser-based dataflow editors out there, such as litegraph.js and NoFlo, which almost all use Canvas or WebGL to render the nodes and edges. This is what you’d expect, since the basic needs of a dataflow editor – absolutely positioning elements on a scrollable canvas, drawing visually pleasing curves, and prioritizing responsive drag-and-drop interactions that involve updating multiple elements at at once – are all relative weaknesses of the DOM, which is designed for hierarchical, nested-box layouts.
But Canvas is a heavy-duty technology, and introduces a sharp discontinuity in a (presumably) otherwise DOM-based application. You lose text selection, accessibility features, all of CSS, and get thrown into “video game world” where you have to construct everything you need from scratch.
For the Underlay project, we wanted to make a data pipeline environment to showcase our algebraic graph data model. The ideal interface we pictured was a dataflow editor where the blocks represented different kinds of transformations, with (strongly typed) data flowing through the edges. But we didn’t want to use a Canvas-based editor, and in particular we wanted to embed the editor into a React application. So we set out to make a dataflow editor with three primary properties:
- General-purpose
- SVG-based
- High-quality React and TypeScript integration
Expanding on these each a little bit:
General-purpose
Most dataflow editors are custom-built for a single application and domain, and can’t easily be re-used by others. It’s not even clear how “general-purpose” a dataflow editor can really be. Just in the small gallery of examples at the beginning of this blogpost there are several incompatible variations on the basic model: some allow cycles, some don’t; some have blocks with multiple outputs, some only allow a single output, and so on. The “dataflow editor” interface is not as standardized as e.g. the “text editor” interface, but we can still do our best to be opinionated when we can get away with it and generic when we can’t.
Text editing is actually a useful point of reference here; it’s maybe the best example of a complex general-purpose interface that has achieved essentially universal adoption. Everybody is so fluent in text editing that we rarely think about “cursors” and “selections” as things that had to be invented, or that could have been something else.
SVG-based
The only real options for rendering graphs on the web are Canvas or SVG. Canvas is definitely the bigger gun, and can perform better on visualizations with lots of data points, but in general we don’t expect dataflow graphs to have tens of thousands of nodes. SVG is lighter-weight and easier to work with, and in the context of React components, SVGs have another advantage: they can be rendered server-side.
High-quality React and TypeScript integration
In order to be effectively general-purpose, we need to expose our editor state in a useful and idiomatic way. In React, this means structuring our editor as a controlled component, with a separate callback prop for handling updates. Our state values should be JSON-serializable so that users can store and read them easily, and our state should be as strongly-typed as we can reasonably manage.
Editor State
What type of state does a dataflow editor have? For example, text editors have just two state components: the value of the text (as a string, an array of lines, or equivalent), and the location(s) of the cursor(s) and/or selection(s). A dataflow editor is more complex, and it’s here that we have to make some decisions about the basic model that we want to work with.
Let’s start with a point of clarification. It feels natural to describe the state of a dataflow editor as a “graph” of “nodes and edges”, but these aren’t quite the same as the usual definition of directed graphs. Dataflow editors have blocks with labelled input and output ports; edges can only connect output ports to input ports (this is different from having edge labels because the ports are labelled on “both sides”). It would be more proper to call this kind of thing a “wiring diagram”, but we’ll continue to use the term “graph” (along with “nodes” and “edges”) in a casual sense to refer to the content of the editor.
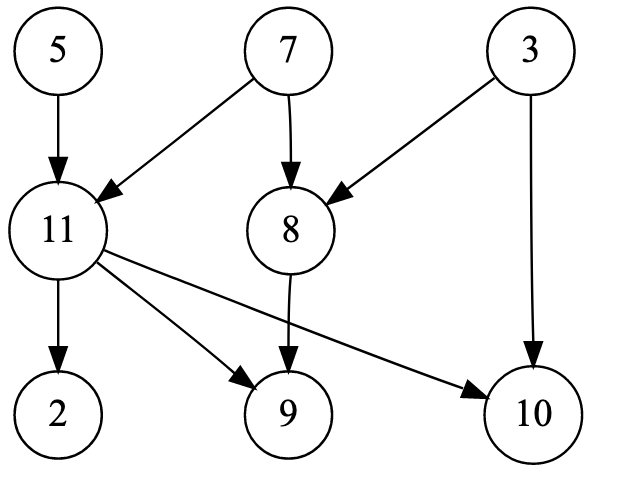
A classical directed graph
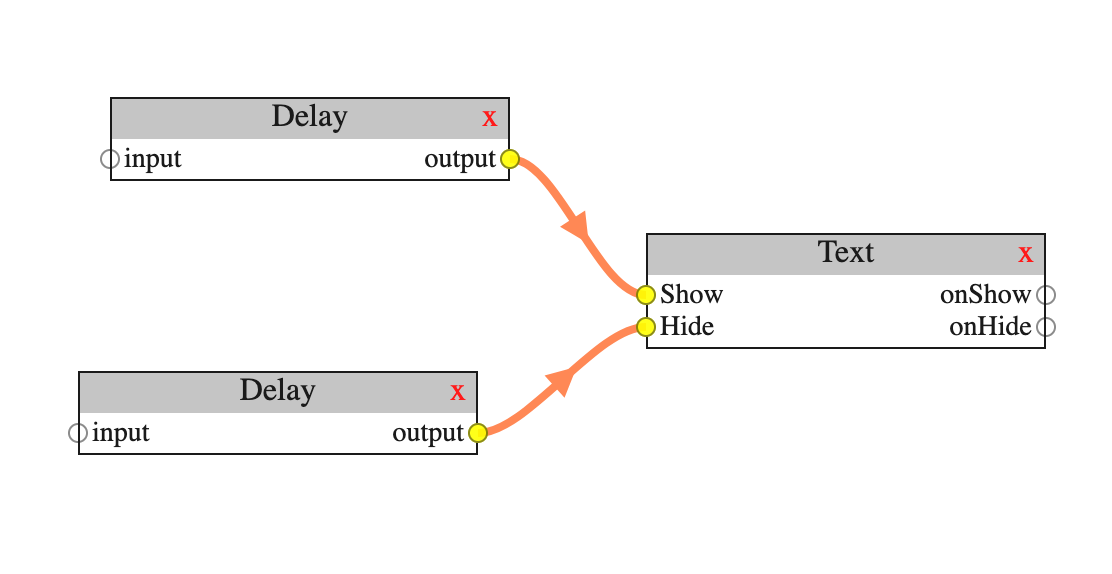
a dataflow editor ‘graph’
Here are some ground rules for the kind of dataflow editor state we’re going to work with:
- nodes have a fixed (non-dynamic) set of named input ports and named output ports
- edges connect output ports to input ports
- an input port can be the target of at most one incoming edge
- an output port can be the source of arbitrarily many outgoing edges
- cycles are allowed; edges can connect any output to any input
With these in place, let’s take a stab at writing out types for our nodes and edges:
type NodeID = string
type EdgeID = string
interface Node {
title: string
backgroundColor: string
position: { x: number; y: number }
inputs: Record<string, EdgeID | null>
outputs: Record<string, EdgeID[]>
}
interface Edge {
source: { id: NodeID; output: string }
target: { id: NodeID; input: string }
}
interface EditorState {
nodes: Record<NodeID, Node>
edges: Record<EdgeID, Edge>
}
The explicit “ports” show up in the types of the edge source and targets: edges connect a specific output port (Edge.source.output) of a specific node (Edge.source.id) to a specific input port (Edge.target.input) of another node (Edge.target.id).
Each node also stores references to its incoming and outgoing edges in the Node.inputs and Node.outputs objects, respectively. Each entry in Node.inputs is an input port and has a value EdgeID | null, while each entry in Node.outputs is an output port and has a value EdgeID[].
These types are an excellent starting point, but let’s try to critically evaluate them. Do they really capture the state we need to represent? Is there too much or too little state? Are there any constraints that we’ve overlooked that could be lifted into the type system? How can we carve this problem closer to its joints?
Legal representation
One standard rule of type design is to make illegal states unrepresentable. How do our types look under this lens?
Not good. Under a literal interpretation, we immediately fail because the types don’t enforce that each EdgeID in every Node.inputs and Node.outputs actually exists in EditorState.edges, or that every Edge.source.id and Edge.target.id actually exists in EditorState.nodes. If we planned to use these types only as JavaScript objects in memory, we could replace the string ID system with direct object references. But we want the state to be JSON-serializable, which means we can’t allow reference cycles in objects and need to use explicit IDs to get this nice flat structure.
Our types also fail the rule in a more significant way because they are so redundant: the values for every Node.inputs and Node.outputs can be derived from EditorState.edges, and vice versa. EditorState essentially represents connections using both an adjacency list and an adjacency matrix – opening the possibility that the two could get out of sync. And even the adjacency list itself is redundant, since every edge shows up once as an input and again as an output.
But even if we tried to deduplicate this, we would run into trouble. If we threw away the adjacency list (Node.inputs and Node.outputs) and kept the adjacency matrix (EditorState.edges), we’d lose the constraint that inputs can accept at most one incoming edge. Of course, we could still say that this needs to be true, but it wouldn’t be reflected in the type system, which is what we really care about. On the other hand, if we flipped it around and kept the adjacency list and threw away the adjacency matrix, we’d find that this is still redundant, since every edge is double-counted: once as an input and again as an output. If we were really persistent and tried throwing away the outgoing Node.outputs and only keeping the incoming Node.inputs, we would preserve the exclusive input constraint, but then empty outputs would be unrepresentable (i.e. there would be no difference between a node with one output that has no outgoing edges and a node with no outputs at all).
All this trouble is simply due to the fact that graphs are inherently awkward to model using regular data structures like objects and arrays. Adjacency matrices and adjacency lists both have pros and cons and are each more convenient for different kinds of uses and more efficient over different kinds of graphs. So one conclusion we could draw is that because the editor state is something that we will expose to the user (here “user” refers to the developer rather than the end-user), and because we don’t know what kinds of things they might want to use it for, exposing both representations is just a nice thing to do.
Another (simpler) justification for keeping the redundancy goes like this: “a dataflow editor deals with nodes and edges, and so the state should have nodes and edges”. This is a pretty strong argument - so strong it’s hard to say what it even is. It appeals to a sense of correspondence; it reminds us that we should prefer types that look like the conceptual models in our heads. When we look at a graph, we tend to visually parse the nodes and edges as separate things, neither subordinate to nor “implied by the state of” the other. Adjacent edges feel like part of the node state, and edges also feel like they have their own identity, so our types should be organized in a similar way.
Beyond Bijections
We can picture the type design process as a search for both a type T and a map f from “conceptual states” to “values of type T”.
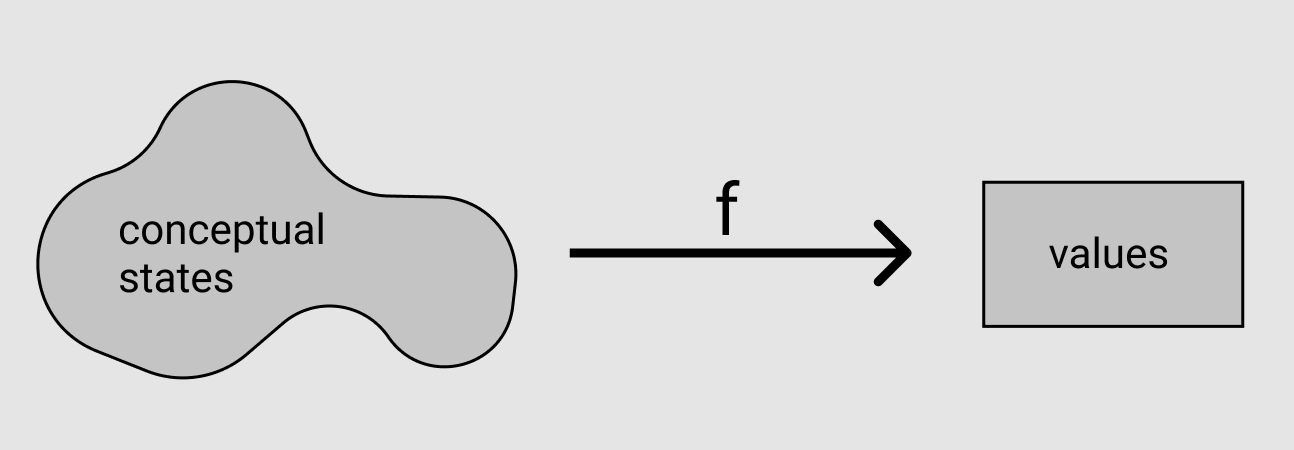
“Making illegal states unrepresentable” is equivalent to requiring that f be surjective – that every value in its codomain has a non-empty pre-image in its domain. We already expect f to be injective (we definitely don’t want two separate conceptual states to be represented by the same value), so… it’s over, right? Isn’t bijectivity the strongest property we could ask for? Is there anything else to even say about f?
Bijectivity is only the end of the road if we think very narrowly about f as a function from one set of elements to another. However neither our conceptual states nor the values we use to represent them exist in a vacuum; they both relate to other kinds of conceptual states and other kinds of values in some larger context. Anyone importing our component is (most likely) going to use their state values to do some other things, like evaluating a graph on the server, and their application is going to present “pipeline graphs” in some relationship to other concepts (as a page, as part of some other resource, with other things attached to it, etc.).
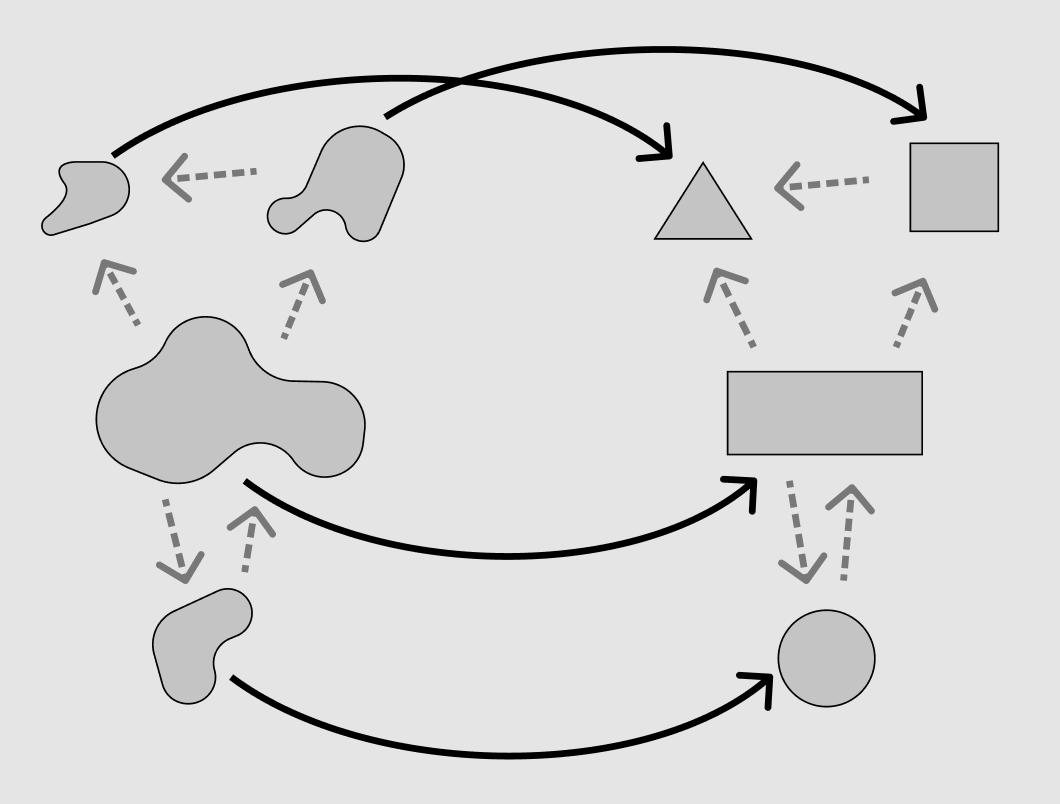
‘Structural correspondence’ is when the system-level mapping from concepts to values is functorial!
This is why the actual structure of our types matters beyond surjectivity on f. A type is not just a set of values; in a computing context it’s also a set of methods on those values. We want those methods to correspond to the conceptual relations the state has as well! This makes using the values more natural (and thereby less error-prone, etc).
The above is a drawn-out attempt at giving a little mathematical substance to an intuition that often gets dismissed or relegated to the status of a “practical tradeoff”. The goal of type design is not to find a perfectly surjective f, and shouldn’t even be thought of as “finding as surjective an f as possible modulo practicality”. The way that the structure of a type for a concept relates to the structure of the types for its related concepts is just as important and just as rigorous a goal as minimizing invalid states.
Showing a little kindness
If we go back and compare our types to the gallery of example dataflow editors in the beginning, things look pretty good. Our state describes everything that we see in the pictures: the node positions, the node titles, the port labels, and the connection structure. We even have background colors, as a treat.
However, there is one structural aspect to dataflow editors that we’re overgeneralizing: dataflow editors always have a fixed set of kinds of nodes. Conceptually, we don’t actually have “a bunch of nodes, each of which has a title, color, and a port configuration”, which is what our types so far would have us believe. What we really have is “a bunch of nodes, each of which is of a certain kind”, and where each kind has a fixed title, background color, and port configuration. Dataflow editors really have two distinct levels of state: an immutable static level that holds a catalog of node kinds, and a mutable dynamic level that represents the graph topology.
What does this mean for our types? If we just wanted to “lift” titles, colors, and port configurations out of each node, we could do something like this:
type KindID = string
type NodeID = string
type EdgeID = string
interface Kind {
title: string
backgroundColor: string
inputs: Record<string, null>
outputs: Record<string, null>
}
interface Node {
kind: KindID
position: { x: number; y: number }
inputs: Record<string, EdgeID | null>
outputs: Record<string, EdgeID[]>
}
interface Edge {
source: { id: NodeID; output: string }
target: { id: NodeID; input: string }
}
interface EditorState {
kinds: Record<KindID, Kind>
nodes: Record<NodeID, Node>
edges: Record<EdgeID, Edge>
}
This is nice – it will mean that node titles and background colors get consolidated – but it only consolidates values and doesn’t help us coordinate our types. If anything, it makes our types even more chaotic because now we have the implicit unenforced constraint that the keys of each Node.inputs are also the keys of the corresponding EditorState.kinds[Node.kind].inputs. If you’re just coming from a JavaScript background, this probably doesn’t seem like anything worth mentioning, but once you become better friends with type systems it feels like nails on a chalkboard. We want the static values all in one place, but we also want TypeScript to know that the type of Node.inputs and Node.outputs depend on the value of Node.kind.
The way to properly coordinate our types is to lift the static part of our state into the type level. For us, this means making EditorState, Node, and Edge all generic in some shared parameter, which we will call Schema.
type Schema = Record<string, { inputs: string; outputs: string }>
The amazing thing about it is that we’re never going to instantiate Schema at the value level. Nowhere in our codebase will we ever deal with some schema: Schema – instead, it’s more like a type’s type. Its only purpose is to be a constraint for a generic parameter S extends Schema that we’ll use when we rewrite Node, Edge, etc.
This is why .inputs and .outputs are both string in Schema and not string[] or Set<string> or Record<string, null> or similar. Node kinds are supposed to declare sets of named ports – so if we were thinking about values that are assignable to the type Schema, we would be concerned, since only concrete, singular strings can be assigned to the type string. But instead we care about types that extend the type Schema. Unions of string literals ("foo" | "bar") are the natural way to represent sets of strings at the type level, and the best type constraint to express “this type can be any union of string literals” is just string. This is one place where type-level programming in TypeScript gets really dangerous: it’s easy to lose track of whether some generic parameter Foo extends string is supposed to be instantiated with just one string literal or a union of them, and this can cause bugs that are hard to diagnose.
To summarize, we have a type Schema that we’ll only ever use it as a generic parameter constraint for concrete types S extends Schema that look like these examples:
// one kind "a" with two inputs "foo" and "bar" and no outputs
type S1 = { a: { inputs: "foo" | "bar"; outputs: never } }
// three kinds "x", "y", and "z"
type S2 = {
// no inputs and one output "hello"
x: { inputs: never; outputs: "hello" }
// no inputs and two outputs "hello" and "world"
y: { inputs: never; outputs: "hello" | "world" }
// one input "FJDKLSFJKSDJFS" and two outputs "hello" and "world"
z: { inputs: "FJDKLSFJKSDJFS"; outputs: "hello" | "world" }
}
Utility Types
When making a large chunk of your codebase generic in some configuration parameter, it’s a really good idea to write a small collection of utility types that you can use as getters instead of directly indexing into your configuration type everywhere. You’re very likely to refactor your big configuration type a few times, and doing lots of type-level programming is actually pretty unsafe (because types aren’t very strongly typed 🙃). Utility types help keep the important logic in a single place that is easier to maintain.
type GetInputs<S extends Schema, K extends keyof S> = S[K]["inputs"]
type GetOutputs<S extends Schema, K extends keyof S> = S[K]["outputs"]
We can use the utility types GetInputs and GetOutputs as accessors, exactly like this code:
const getInputs = (s, k) => s[k].inputs
const getOutputs = (s, k) => s[k].outputs
const s = { a: { inputs: ["foo", "bar"], outputs: [] } }
const _a = getInputs(s, "a") // ["foo", "bar"]
const _b = getOutputs(s, "a") // []
… except “at the type level”:
type S = { a: { inputs: "foo" | "bar"; outputs: never } }
type _A = GetInputs<S, "a"> // "foo" | "bar"
type _B = GetOutputs<S, "b"> // never
Avicii - Levels (Original Mix)
So far, we’ve said that we want to factor out the static part of our state into its own value, and that we want to “lift” this part of our state into the type level by making everything generic.
It’s easy to look at this situation and conclude that we should use the type of the static state value as the generic parameter constraint, like this:
type Config = Record<KindID, Kind>
interface EditorState<C extends Config> {
config: C
nodes: Record<NodeID, Node<C>>
edges: Record<EdgeID, Edge<C>>
}
… after all, our whole goal is to get the type system to be aware of this static value, so… shouldn’t we make things generic in that static value’s type? However it is crucial to understand that we need to write two different types to achieve this: one type for the value level and another type for the type level. This is probably an infuriating thing to read, so let’s unpack it.
“One type for the value level” means that when people use our editor as a React component, they’re going to provide it with some prop (called kinds) that has all the runtime data about the catalog of different node kinds, and this prop will be of some type. The “runtime data” that is in this catalog includes, for each node kind, the display title, the background color, and the names of the input and output ports. These are all the values we need in order to actually render a node as an SVG.
“Another type for the type level” means that, as a part of our quest to make TypeScript aware that the type of Node.inputs depends on the value of Node.kind, we’re going to add a generic parameter S extends Schema to all of our state types. S acts as a type variable; we can use it in our type definitions “as if” it were instantiated as some concrete subtype of Schema. Our goal is to use S to share data across our state types, but this means that we have to “store” that data as a concrete subtype of Schema. Not “as a value of a concrete subtype of Schema” – literally as a concrete subtype of Schema.
Representing data using types is just a different game than representing data using values: as we saw earlier, you might represent “a collection of strings” as ["foo", "bar", "baz"] as a JavaScript value, but if you need to represent the same collection as a type you have to say something entirely different ( "foo" | "bar" | "baz"). S, like Schema, is never used as the type of an actual JavaScript value. Schema functions as a “type-level type”; S functions as a “type-level value”.
So what data needs to be shared across our state types? It turns out that not everything in the runtime catalog needs to be lifted into the type level. For example, the type Node doesn’t depend on its kind’s background color or display title, but it does depend on the value of its input port names (since those form the keys of Node.inputs). The type level only needs to know about the port configurations.
It’s easy to get disoriented with these things! A good general tip if you get confused about a type is to ask yourself whether it’s a value-level type, a type-level value, a type-level function (ie a generic type), or a type-level type (ie a generic parameter constraint).
Developer experience
We said that “we need two separate types” for the value and type levels – isn’t this a red flag? Will users have to configure the same data twice?
import { Editor } from "react-dataflow-editor"
// This would be a terrible thing to ask of people!
type MySchema = { add: { inputs: "a" | "b"; outputs: "sum" } }
const kinds = {
add: {
inputs: { a: null, b: null },
outputs: { sum: null },
backgroundColor: "lavender",
title: "Addition"
}
}
function Index(props: {}) {
return <Editor<MySchema> kinds={kinds} ... />
}
Not if we play our cards right! Let’s think about our constraints here:
- we have to get the same data (about port configuration for each kind) into both the value level and the type level
- we definitely can’t start with a type and then derive a value from it, because all of this ultimately runs as JavaScript code, which doesn’t know anything about what we’re doing type-wise
… so if we want to avoid defining the same things twice, we have to try to derive a type-level version of the port configuration data from a value-level version that the user provides us with.
Let’s go back and look at some examples again. We want to derive a type that looks like this
type S = { add: { inputs: "a" | "b"; outputs: "sum" } }
… from a value that looks like this:
const kinds = {
add: {
inputs: { a: null, b: null }
outputs: { sum: null },
backgroundColor: "lavender",
title: "Addition"
}
}
You might look at this and think “Ok, great! Let’s make our top-level component generic in a parameter K extends Kinds, have it take a prop kinds: K, and write a generic type MakeSchema<K extends Kinds> that turns K into S! Here’s a diagram!”
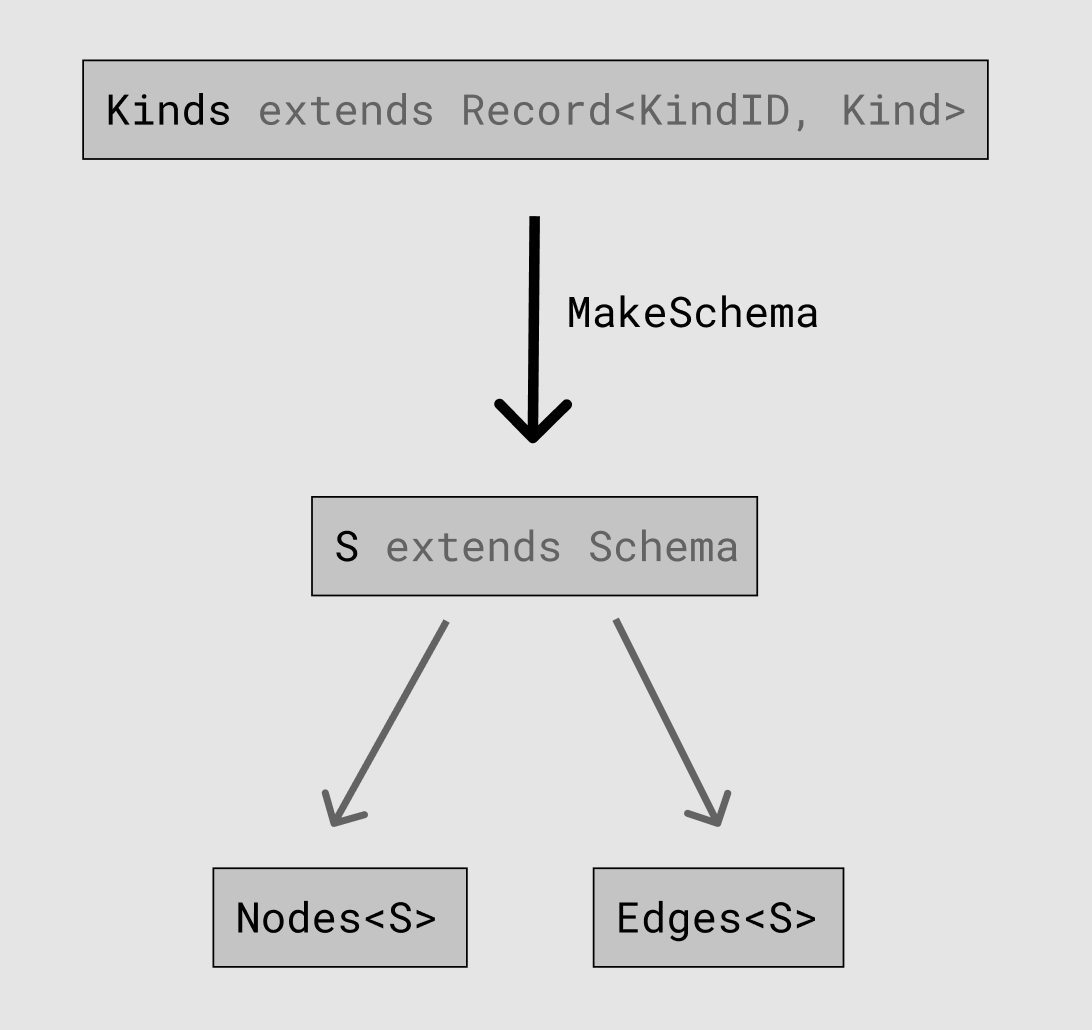
This is the right way to anticipate the logical flow of data: we’re going to use the value of kinds to derive a type S, and then use S to parametrize Nodes and Edges. But, for reasons beyond the scope of this blog post, that approach won’t actually work. And even if it did, it would make things more complicated than they need to be.
Something a little freaky about the type system is that the logical flow of data doesn’t have to correspond to the direction of the lexical references; TypeScript is willing to do a lot of “backward” inference on our behalf. It turns out that we can just write kinds: Kinds<S extends Schema> just like the rest of our application, and TypeScript will run the dotted arrow in reverse.
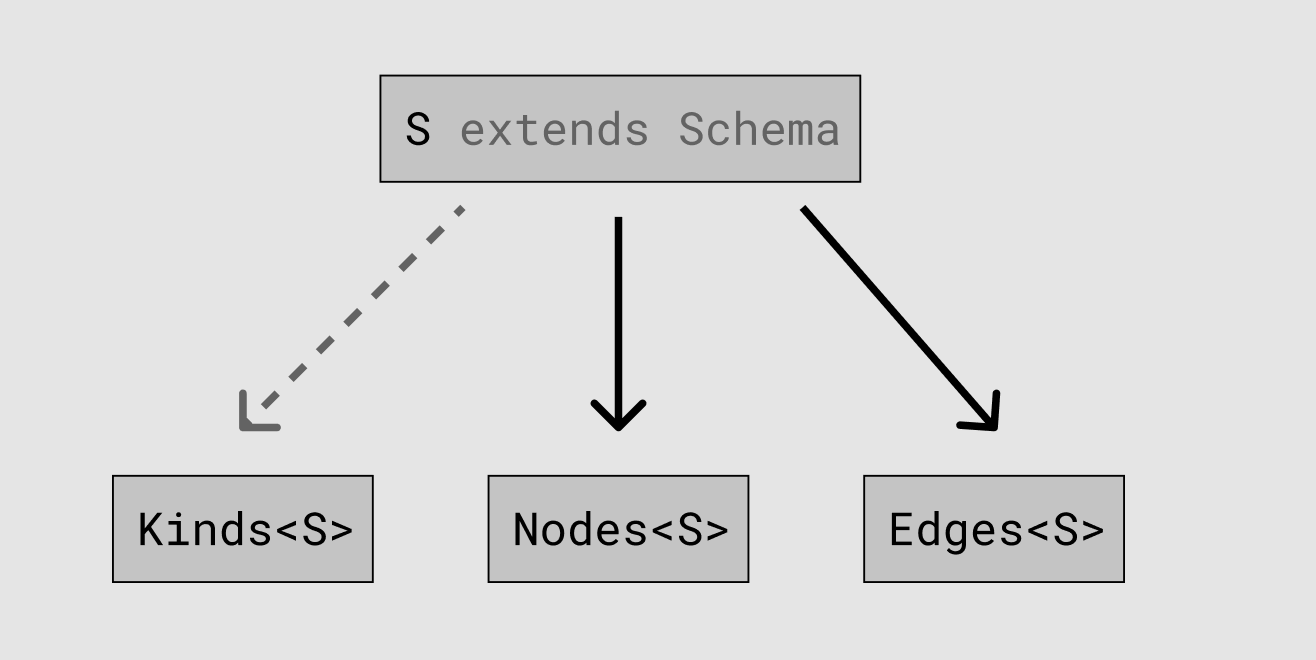
In other words, we can write our type for the prop kinds as if it depended on the type S, even though in reality we need things to “happen” in the opposite order.
Let’s rewrite Kinds to depend on S:
interface Kind<I extends string, O extends string> {
title: string
backgroundColor: string
inputs: Record<I, null>
outputs: Record<O, null>
}
type Kinds<S extends Schema> = {
[K in keyof Schema]: Kind<GetInputs<S, K>, GetOutputs<S, K>>
}
Awesome. Now, when a user imports our component and tries to use it:
import { Editor } from "react-dataflow-editor"
const kinds = {
add: {
inputs: { a: null, b: null },
outputs: { sum: null },
backgroundColor: "lavender",
title: "Addition"
}
}
function Index(props: {}) {
return <Editor kinds={kinds} ... />
}
… the compiler will say…
-
Hi there! I see you’re using a generic function
Editoras a JSX component without explicitly giving me a concrete type for the generic parameterS extends Schema. I’m going to try to infer a concrete type for this parameter by looking at the types of the props you’ve given me. Wish me luck! -
Ok, I’m here looking at the
kindsprop. You passed in a raw object that you defined earlier, and back then I used my regular type inference rules to give it the type:declare const kinds: { a: { inputs: { a: null; b: null } outputs: { sum: null } backgroundColor: string title: string } }… which you’re now telling me should be assignable to the expression
Kinds<S>. I’m going to try to see if I have enough information to infer whatSis from this. -
Alright I think I’ve got it figured out. By working backwards I’ve concluded that
Sshould be the concrete type{ add: { inputs: "a" | "b"; outputs: "sum" } }. I’m going to go ahead a propagate this through the rest of the component’s types, and I’ll let you know if I find any conflicts.
It’s possible to make a generic component where no single prop’s value will determine the concrete type of the parameter, and instead to “spread the inference out” across several props. It’s also possible to make a component that is generic in several parameters. But it’s really not desirable to get into a “many-to-many” inference situation – that’s just asking for trouble and would be extremely hard to debug. The simplest way to keep your types manageable is to centralize everything:
- consolidate all of the type-level data you need into a single global generic parameter
- write an accessor utility type for every facet of the parameter that you need to use
- use a single dedicated “configuration” prop or argument, also generic in the same parameter, to drive inference of the parameter’s concrete type
Making the types go up
Another thing that might stick out is that we’re asking users to configure each kind’s input and output ports by giving us an object with port names as keys and null for every value, like { a: null; b: null }. This a weird choice. Wouldn’t ["a", "b"] be simpler?
The problem this is working around has to do with TypeScript’s default heuristics for assigning types to raw (unannotated) values. For example, if we write…
const foo = { a: null, b: null }
… TypesScript will look at this and say “Cool. Since you didn’t tell me otherwise, I’m going to assign foo the type { a: null, b: null }”. But if we instead wrote…
const bar = ["a", "b"]
… TypeScript will give bar the type bar: string[]! The actual values "a" and "b" – which are the things we’re trying to share with the type level in the first place – just get ignored.
TypeScript does have tuple types, so we could explicitly write something like this:
const bar: ["a", "b"] = ["a", "b"]
… or this:
const bar: ("a" | "b")[] = ["a", "b"]
… or even this:
const bar = ["a", "b"] as const
… but our whole goal was to centralize the port configuration in one place, without having to duplicate it on the type level, and without being rude to our users (as const etc is not something we should expect people to be familiar with). Ideally, we want configuration values to be regular JavaScript objects that expose the port configuration to the type level via TypeScript’s default typing heuristics. This requires a little creative restructuring and results in the slightly more awkward { a: null, b: null }.
Leveraging these defaults to “drive” generics in a codebase is an extremely powerful design pattern. Naively we think of types as living “on top of” values, and that good code would be code with “100% type coverage”, where every single value has an explicit type annotation, and where the role of the TypeScript compiler is to run around checking all your work. A more nuanced view of the type system is that it is less an authoritarian ruler and more a partner in crime – a place that you can both push data to and pull data from. Often we need to design things in reverse and make types bubble up from (deliberately unannotated) values; it’s is the best way to coordinate the two levels.
Another place you see this pattern is in the Prisma ORM client, which has some insanely high-quality TypeScript integration. Prisma knows what schema all of your tables are, so it knows how to autocomplete your query objects. But their query methods are also all generic: they use the actual value of the .select property (which you provide as a regular unannotated JavaScript object) to infer a precise return type for the whole method.
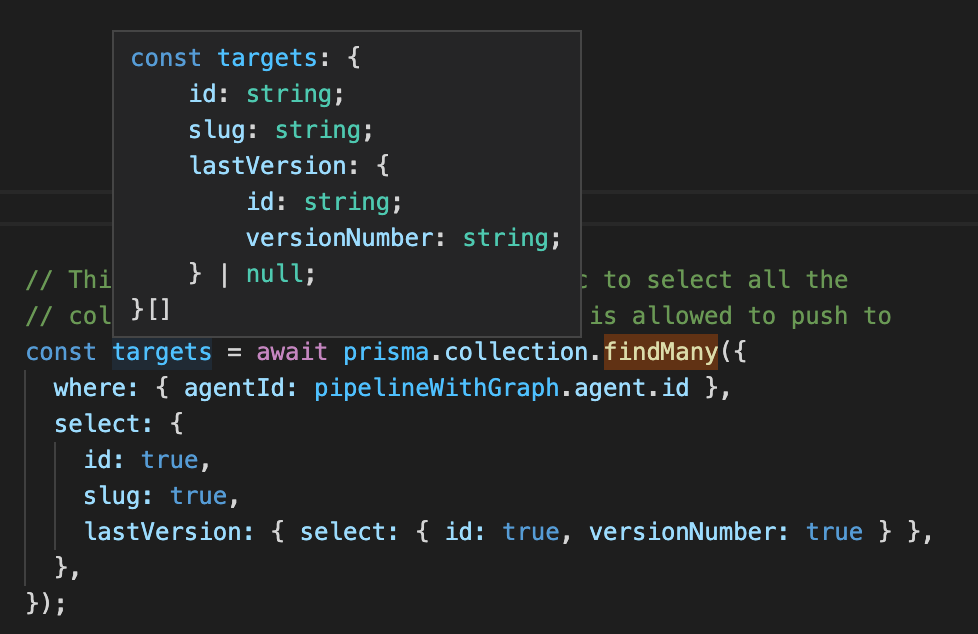
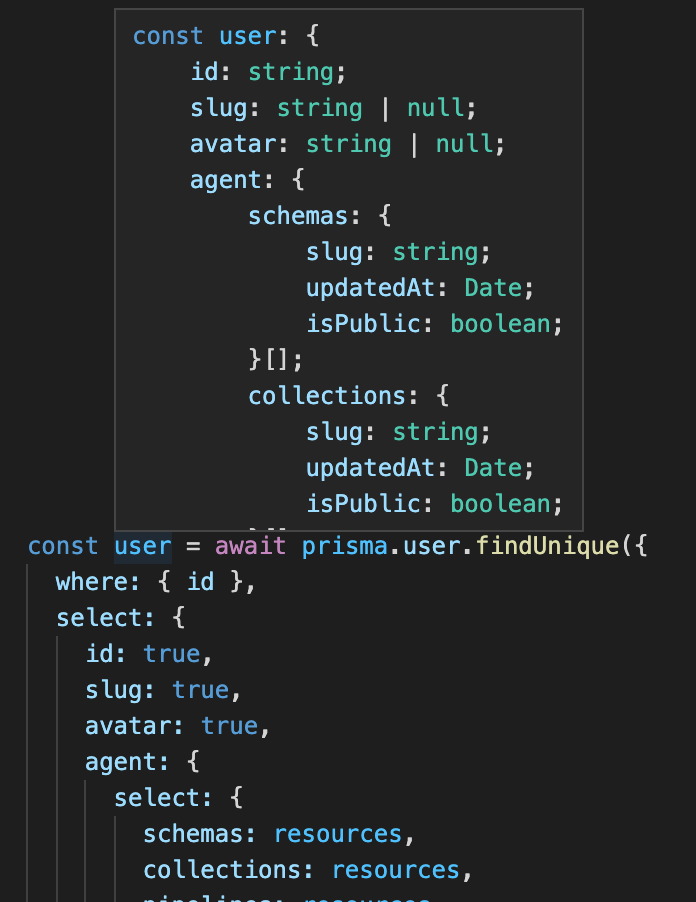
This makes for a pretty phenomenal developer experience: end-to-end strong typing, into and out of your database, all in your IDE. And you can see traces of the same problem we had to work around! You might have expected .select to take an array of string property names, but object keys have stronger type behavior, so instead it’s all { [property]: true }.
Redistributing unions
There’s just one last problem we have to solve.
Given our general plan of “making everything generic in S”, you’d expect that we would write Node like this:
interface Node<S extends Schema, K extends keyof S = keyof S> {
kind: K
inputs: Record<GetInputs<S, K>, null | string>
outputs: Record<GetOutputs<S, K>, string[]>
position: { x: number, y: number }
}
Intuitively, this says all the right things. Node is parametrized by two type variables – a schema and a kind K in that schema – and it has an explicit .kind: K along with .inputs and .outputs objects that have key domains GetInputs<S, K> and GetOutputs<S, K>, respectively.
But we should check to make sure that this type actually behaves the way we want. First let’s manually instantiate a concrete schema to play with.
type MySchema = {
add: { inputs: "a" | "b"; outputs: "sum" }
div: { inputs: "dividend" | "divisor"; outputs: "quotient" | "remainder" }
}
type MySchemaNodeAdd = Node<MySchema, "add">
Great. If we inspect (just by hovering over the type variable in VSCodium) the concrete type MySchemaNodeAdd, we see:
type MySchemaNodeAdd = {
position: { x: number; y: number };
kind: "add";
inputs: Record<"a" | "b", string | null>;
outputs: Record<"sum", string[]>;
}
Awesome! What if we don’t specify a kind? When we defined Node we gave the second parameter a default value keyof S – how does that look?
type MySchemaNode2 = Node<MySchema>
… inspecting this we see…
type MySchemaNode2 = {
position: { x: number; y: number };
kind: keyof MySchema;
inputs: Record<"a" | "b" | "dividend" | "divisor", string | null>;
outputs: Record<"sum" | "quotient" | "remainder", string[]>;
}
Gah! This is not what we wanted. TypeScript made our our kinds “collapse”, which kind of defeats our whole goal of making the type of .inputs depend on the value of .kind.
The specific use case we’re trying to support is discriminating on node kinds. When a user imports our component and receives a nodes: Record<NodeID, Node<S>> in the onChange callback, we want them to be able to iterate over the entries, and, for each node, do something like this:
for (const [id, node] of Object.entries(nodes)) {
if (node.kind === "add") {
// At this point, TS should know that node.inputs
// is of type { a: null | EdgeID; b: null | EdgeID }
// and that node.outputs is of type { sum: EdgeID[] }
} else if (node.kind === "div") {
// And at *this* point, TS should know that node.inputs
// is of type { dividend: null | EdgeID; divisor: null | EdgeID }
// and that node.outputs is of type
// { quotient: EdgeID[]; remainder: EdgeID[] }
} else {
// And here, TS should think that node is the never type!
throw new Error("Invalid node kind")
}
}
… and TypeScript will only do this if the type of Node<S, keyof S> keeps the properties grouped:
// This is what we need!!
type MySchemaNode2 =
| {
kind: "add"
position: { x: number; y: number }
inputs: Record<"a" | "b", string | null>
outputs: Record<"sum", string[]>
}
| {
kind: "div"
position: { x: number; y: number }
inputs: Record<"dividend" | "divisor", string | null>
outputs: Record<"quotient" | "remainder", string[]>
}
In other words, we want a union of objects, not an object of unions.
Controlling the way unions distribute can be one of the more frustrating parts of type-level programming in TypeScript. Fortunately, a relatively simple tactic will work for us – we just create an intermediate “index object” and then immediately index on it:
type Node<S extends Schema, K extends keyof S = keyof S> = {
[k in K]: {
kind: k
inputs: Record<GetInputs<S, k>, null | string>
outputs: Record<GetOutputs<S, k>, string[]>
position: { x: number; y: number }
}
}[K]
This effectively “forcibly distributes” over K when it’s a union of string literal types. Now when we evaluate Node<S> we get exactly what we wanted:
type MySchemaNode2 =
| {
kind: "add"
position: { x: number; y: number }
inputs: Record<"a" | "b", string | null>
outputs: Record<"sum", string[]>
}
| {
kind: "div"
position: { x: number; y: number }
inputs: Record<"dividend" | "divisor", string | null>
outputs: Record<"quotient" | "remainder", string[]>
}
Great success!
Bringing it all back home
All the pieces are finally on the table; let’s put them together.
// Our global generic parameter constraint
type Schema = Record<string, { inputs: string; outputs: string }>
// Our accessor utility types
type GetInputs<S extends Schema, K extends keyof S> = S[K]["inputs"]
type GetOutputs<S extends Schema, K extends keyof S> = S[K]["outputs"]
// The values that we need for each node kind.
// Let's make it all read-only, just for good measure.
type Kind<I extends string, O extends string> = Readonly<{
title: string
backgroundColor: string
inputs: Readonly<Record<I, null>>
outputs: Readonly<Record<O, null>>
}>
// Our "configuration property" that will drive inference of S.
// Let's make it read-only too.
type Kinds<S extends Schema> = {
readonly [K in keyof Schema]: Kind<GetInputs<S, K>, GetOutputs<S, K>>
}
// GetSchema turns a concrete Kinds<S> back into S
// This is useful for users who want to store the editor state
// somewhere, and need to get a concrete schema from their
// configuration object
type GetSchema<T extends Kinds<Schema>> = {
[k in keyof T]: T[k] extends Kind<infer I, infer O>
? { inputs: I; outputs: O }
: never
}
type NodeID = string
type EdgeID = string
// Each node now knows exactly which properties its
// .inputs and .outputs objects have!
type Node<S extends Schema, K extends keyof S = keyof S> = {
[k in K]: {
kind: k
inputs: Record<GetInputs<S, k>, null | string>
outputs: Record<GetOutputs<S, k>, string[]>
position: { x: number; y: number }
}
}[K]
type Source<S extends Schema, K extends keyof S = keyof S> = {
id: NodeID
output: GetOutputs<S, K>
}
type Target<S extends Schema, K extends keyof S = keyof S> = {
id: NodeID
input: GetInputs<S, K>
}
// Since edges don't store the kinds of their
// sources and targets, we don't need to re-index
// them in the same way we did for nodes.
// Don't worry too much about SK and TK.
type Edge<
S extends Schema,
SK extends keyof S = keyof S,
TK extends keyof S = keyof S,
> = {
source: Source<S, SK>
target: Target<S, TK>
}
interface EditorState<S extends Schema> {
nodes: Record<NodeID, Node<S>>
edges: Record<EdgeID, Edge<S>>
}
interface EditorProps<S extends Schema> {
kinds: Kinds<S> // static, immutable
state: EditorState<S> // dynamic, mutable
}
Along the way we’ve sketched out our external interface too!
import { Editor } from "react-dataflow-editor"
// Just objects! No funny business!
const kinds = {
add: {
inputs: { a: null, b: null },
outputs: { sum: null },
backgroundColor: "lavender",
title: "Addition"
},
div: {
inputs: { dividend: null, divisor: null },
outputs: { quotient: null, remainder; null },
backgroundColor: "darksalmon",
title: "Division"
}
}
function Index(props: {...}) {
// ...
return <Editor kinds={kinds} state={...} />
}
Editor Actions
In the introduction, we mentioned text editors as an example of a “complex general-purpose interface”. This interface is an abstract thing with two basic parts:
- a state
- a grammar of actions
We already mentioned the state in text editors (lines + cursors/selections), and we hammered out an analogous state for our pipeline editor (with both static and dynamic parts). Now let’s talk about actions!
Actions are a grammar of discrete state transitions. In a text editor, there are several ways you can modify the state:
- Move the cursor
- Select/unselect text
- Cut/Copy/Paste
- Insert text at cursor
- Replace selection with text
- Delete character/word/line backward/forward
- Undo/Redo
- ???
… the list is actually pretty long, and each of these come with a bundle of fantastically complicated edge cases even in the simplest ASCII-only left-to-right contexts (text editing hates you too).
These actions are all still abstract in a certain sense. They represent the different ways that the state can be changed, but not how those changes are initiated by the user. With text editors, most of them can be done in multiple ways - using the either the keyboard or the GUI somehow. As a result, text editors usually implement some kind of command/dispatch pattern, where all state changes are represented as reified objects, and applied using a central dispatch method. This makes it easier to reliably initiate the same change in multiple ways, along with other practical benefits like general extensibility, like letting users intercept or modify actions before they’re applied.
This is essentially the Redux architecture. We’re not actually going to use any Redux libraries, but we will implement the same three basic things that we would in a (TypeScript) Redux application:
- concrete types for each of our abstract actions
- constructor functions for each of the concrete action types
- a reducer function that applies an action to a state value
This also means that instead of a onChange: (value) => void callback like you’d expect to find in a controlled React component, our top-level Editor component is going to take something a little different: a dispatch: (action: EditorAction<S>) => void callback.
This makes this a little more complex for our users: in addition to having to store the state on their own (as with any controlled component), they also have to assemble their own reducer function and their own dispatch method. We can make this as easy as possible for them by exporting reduce function with this signature:
declare function reduce<S extends Schema>(
kinds: Kinds<S>,
state: EditorState<S>,
action: EditorAction<S>,
): EditorState<S>
… so that typical usage can look something like this:
import {
Editor,
reduce,
EditorState,
GetSchema,
EditorAction,
} from "react-dataflow-editor"
const kinds = { /* ... */ }
type S = GetSchema<typeof kinds>
function MyComponent({}) {
const [state, setState] = useState<EditorState<S>>({nodes: {}, edges: {}})
const dispatch = useCallback((action: EditorAction<S>) => {
setState(reduce(kinds, state, action))
}, [state])
return <Editor kinds={kinds} state={state} dispatch={dispatch} />
}
This is a little extra overhead, but it gives the user a clear place to insert their own editing logic – maybe they want to open a confirmation dialog before deleting nodes, or prevent creating more than one node of a certain kind, or enforce some kind of type-checking on edge connections.
Our top-level editor component now takes three props
interface EditorProps<S extends Schema> {
kinds: Kinds<S> // static, immutable
state: EditorState<S> // dynamic, mutable
dispatch: (action: EditorAction<S>) => void
}
… and we’ll pass this dispatch prop all the way down through the entire component tree, so that we have access to it everywhere. Unfortunately we can’t use React contexts for this, since contexts don’t work (and couldn’t conceptually work) with generically typed values, so we have to do it the old-fashioned way.
Actions
Our dataflow editor state is significantly more complex than a text editor’s, but fortunately our grammar of actions is much simpler. We just have two classes of things – nodes and edges – and we can create, move, and delete them.
Some of our actions have to be generic in a parameter S extends Schema; others don’t need to access S. We could make them all generic in S for consistency, but introducing an unused generic parameter is pretty bad practice. This means our combined EditorAction type looks like this:
type EditorAction<S extends Schema> =
| CreateNodeAction<S>
| MoveNodeAction
| DeleteNodeAction
| CreateEdgeAction<S>
| MoveEdgeAction<S>
| DeleteEdgeAction
For each of these, we’ll write out the action type and show an example of a user initiating the action using the GUI (although any of them could just as well be bound to the keyboard).
In the examples, we’ve augmented our dispatch method we provide to the top-level editor component to console.log every action that gets dispatched (in addition to applying it and setting the new state).
Create a node
Creating a node is an action that takes two arguments: a kind of node to create, and a position on the canvas.
|
|
create a node
Delete a node
Deleting a node is an action that takes one argument: a node ID.
|
|
delete a node
Move a node
Moving a node is an action that takes two arguments: a node ID and a position on the canvas.
|
|
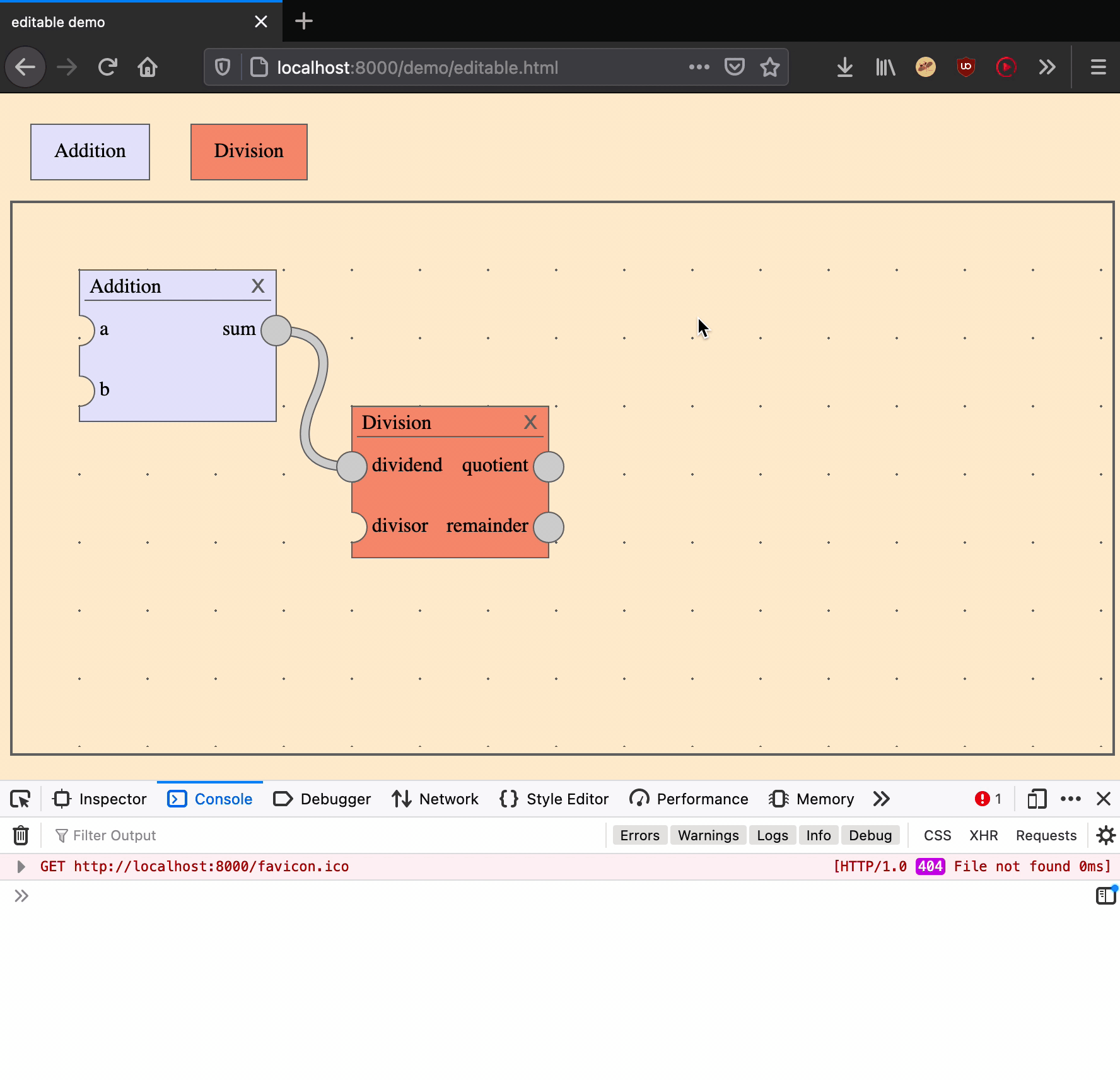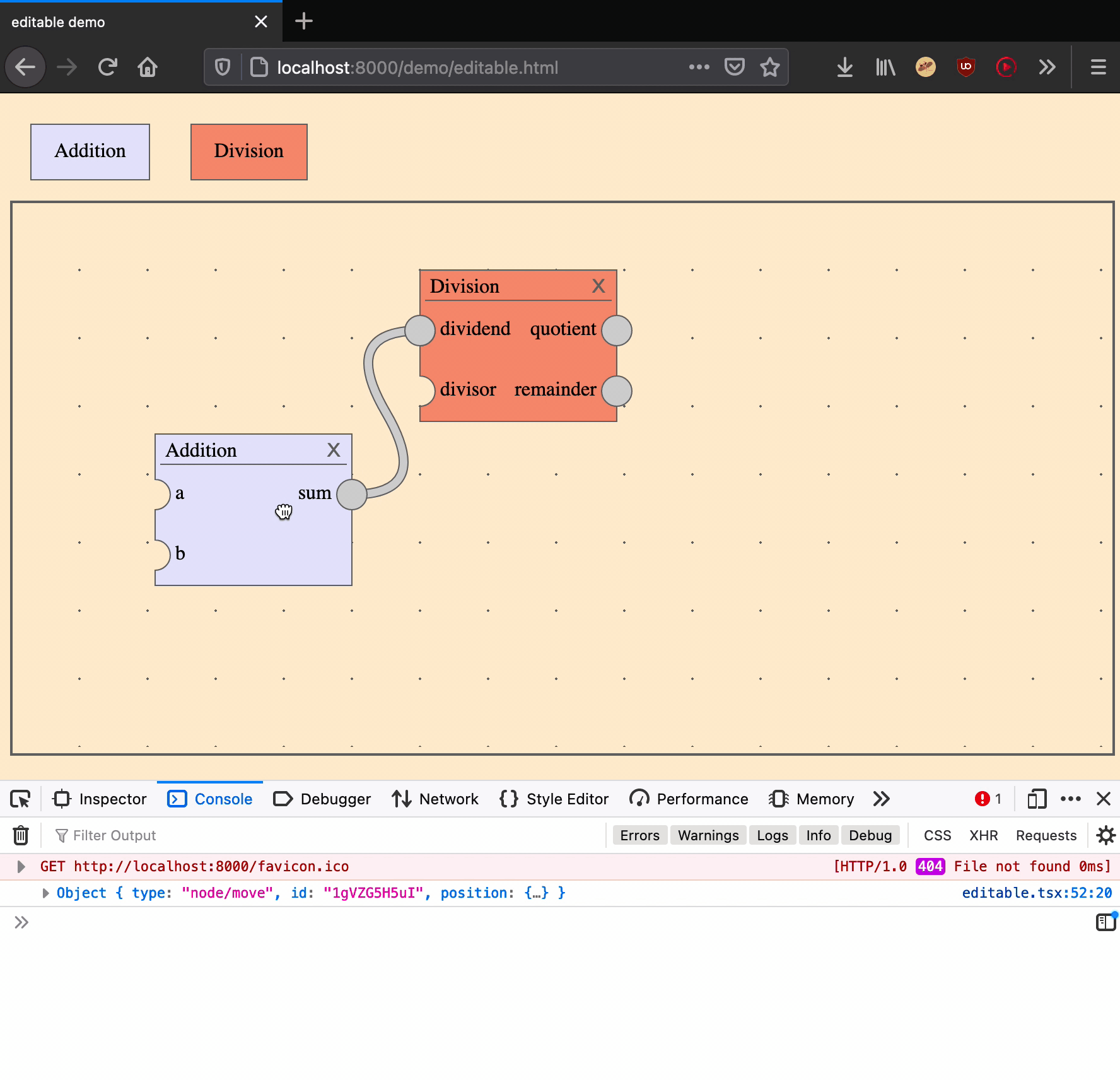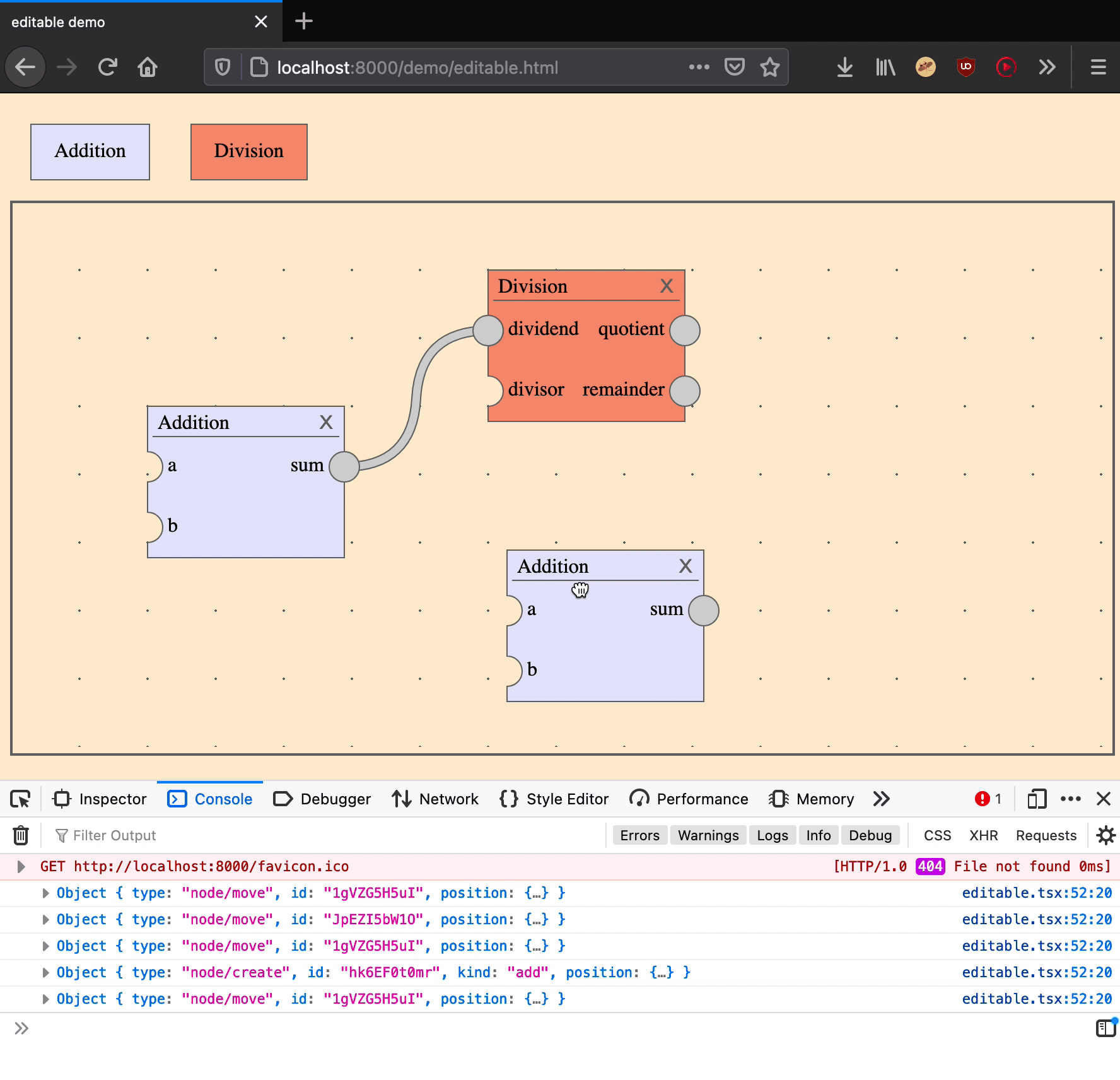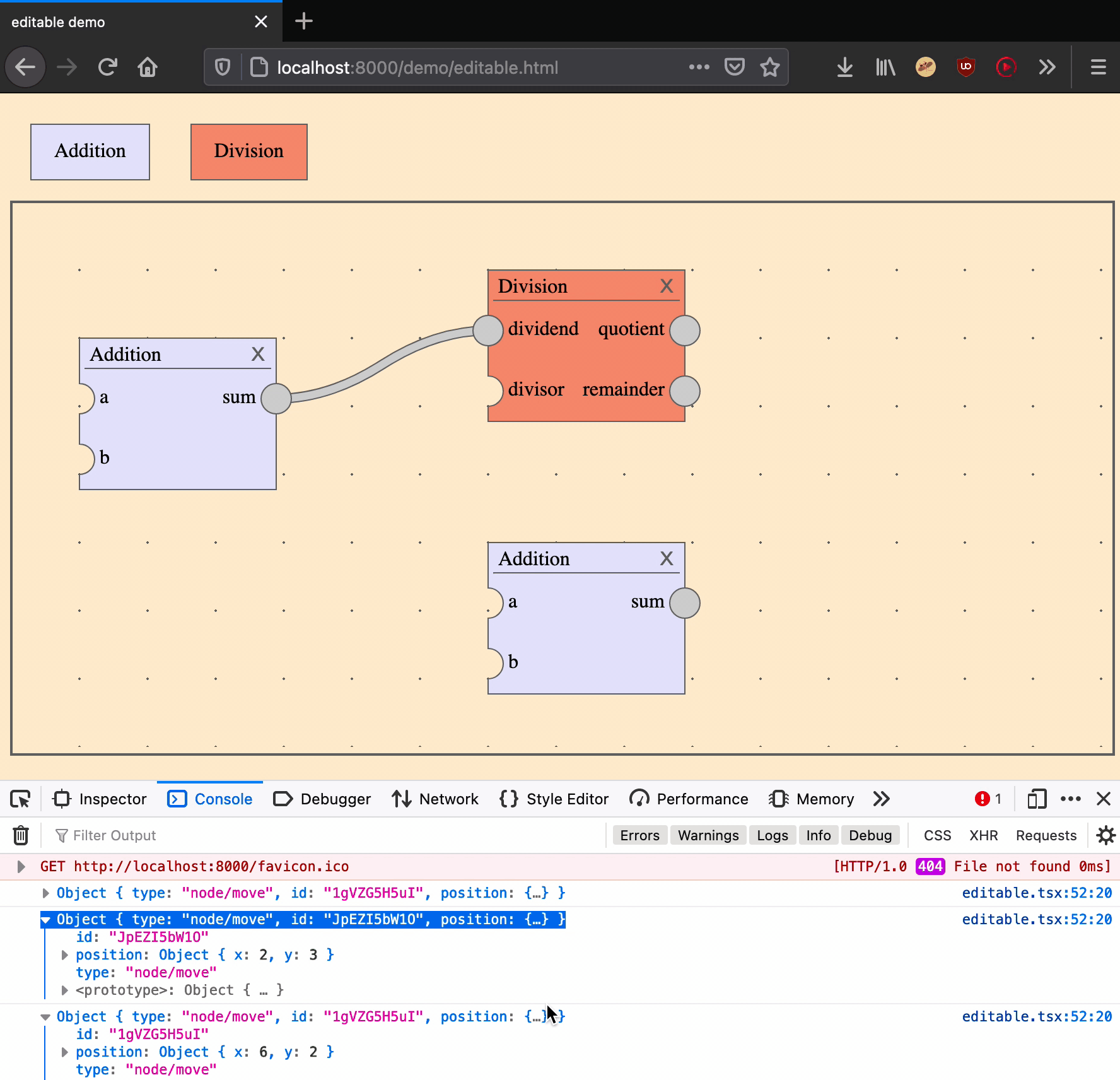
move a node
Create an edge
Creating an edge is an action that takes two arguments: a source output port and a target input port.
|
|
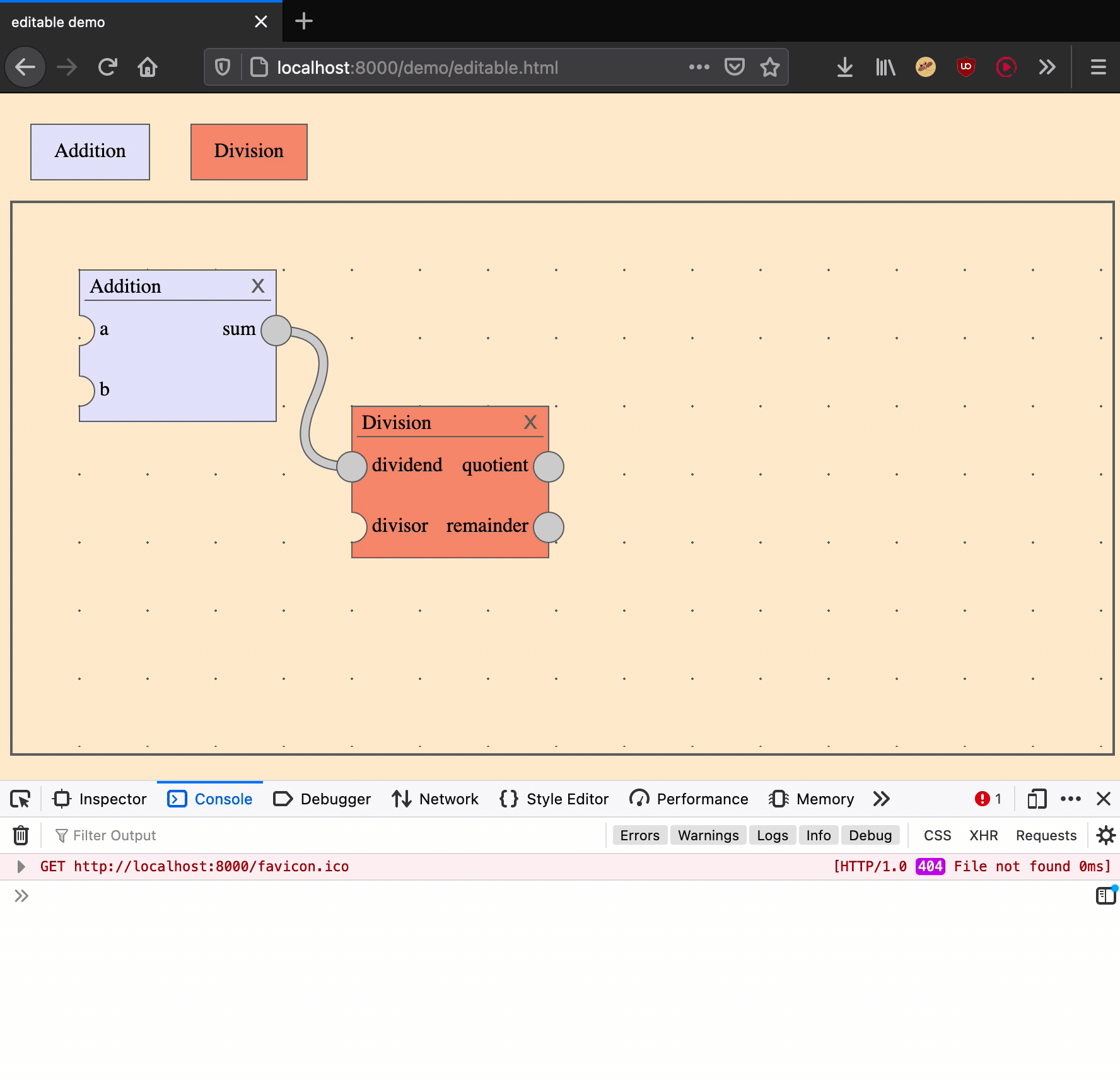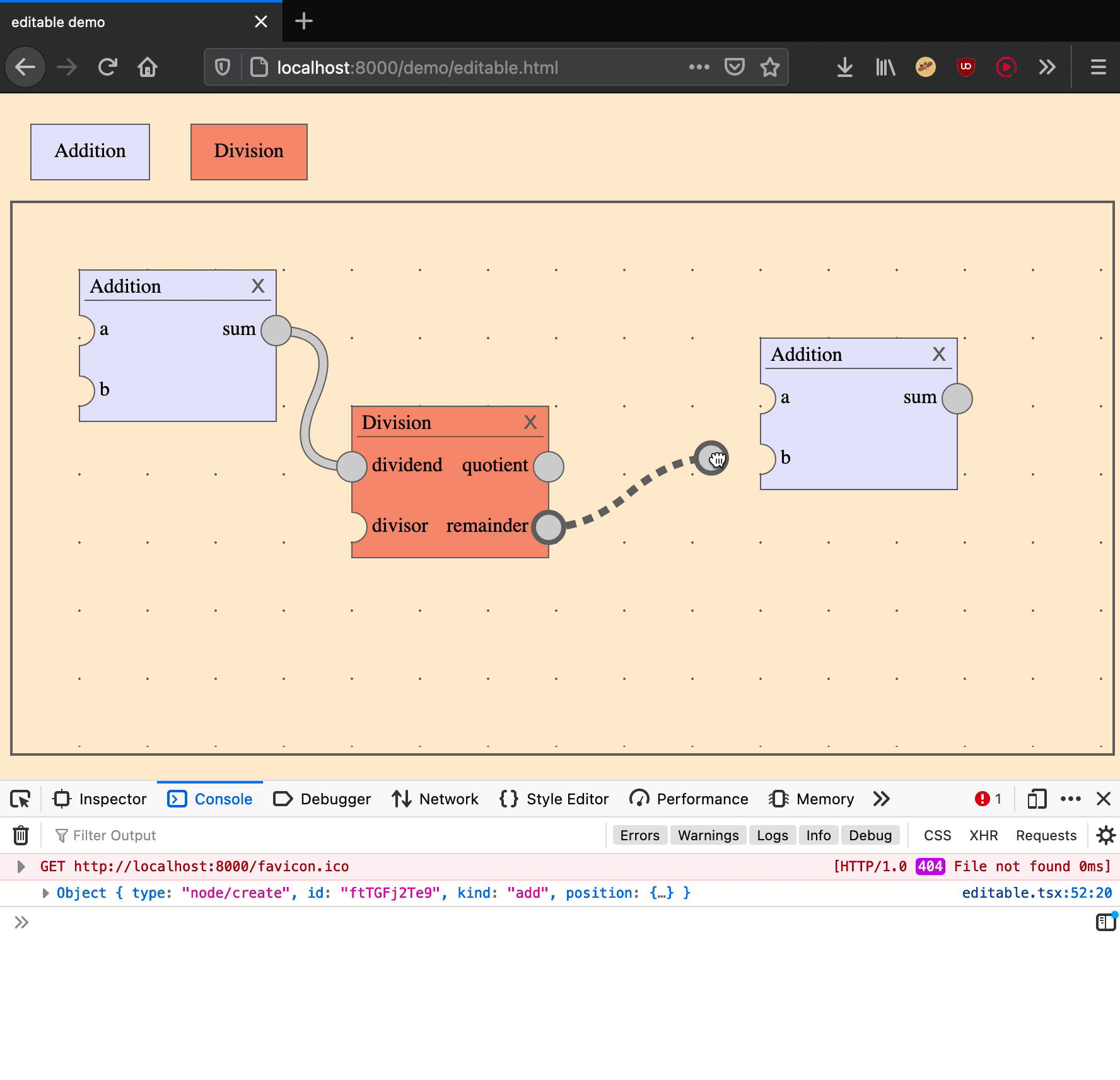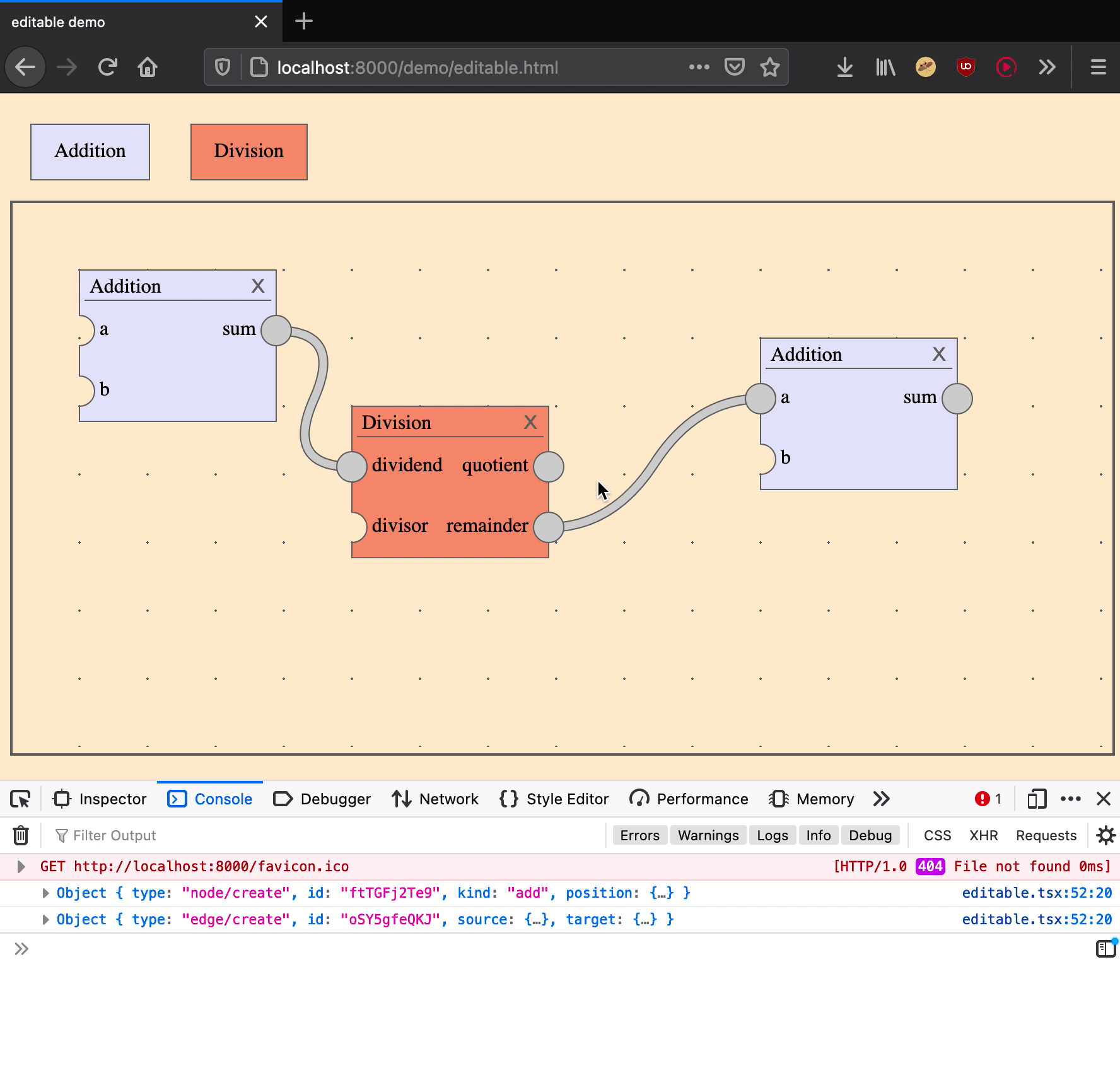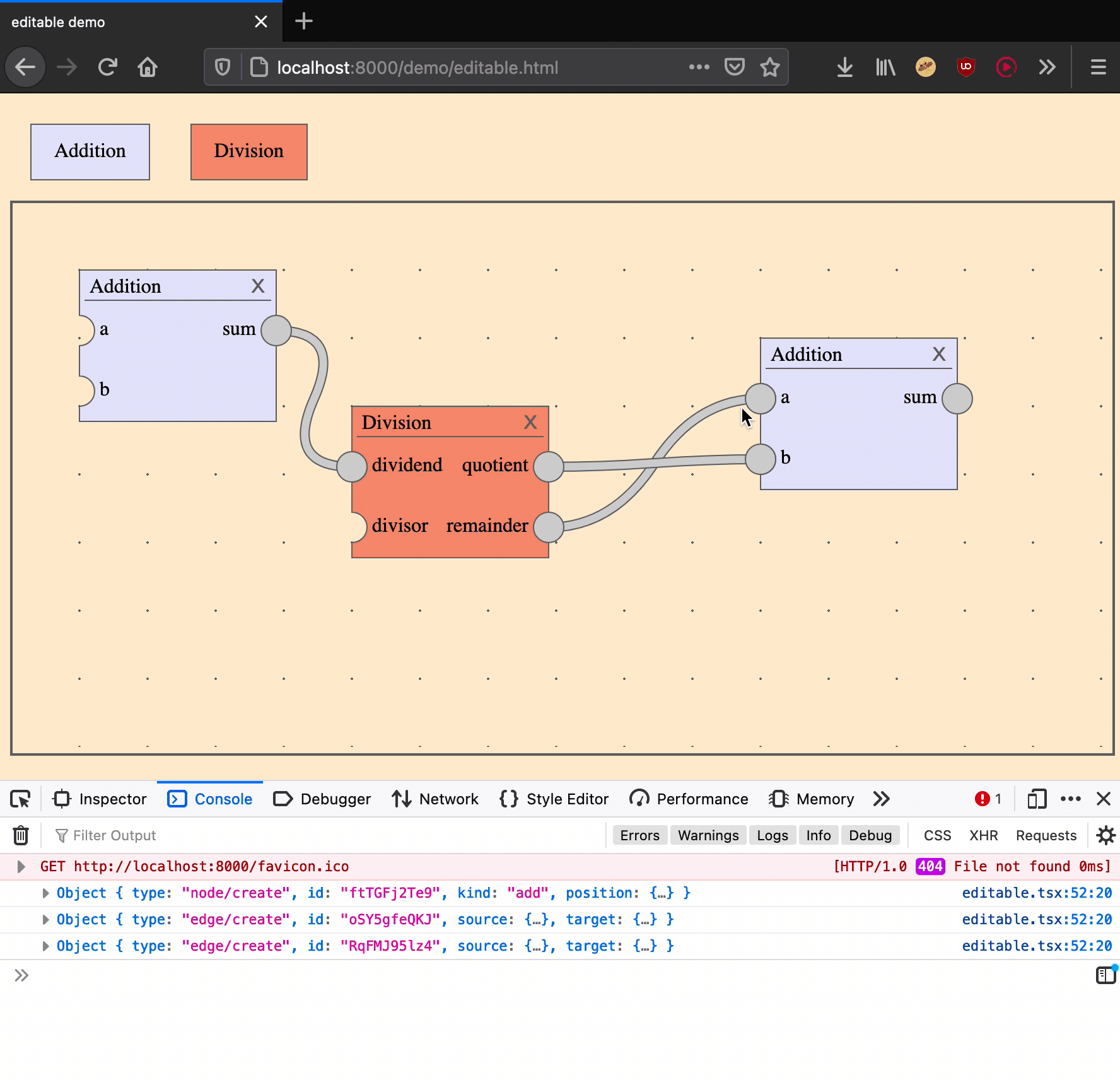
create an edge
Delete an edge
Deleting an edge is an action that takes one argument: an edge ID.
|
|
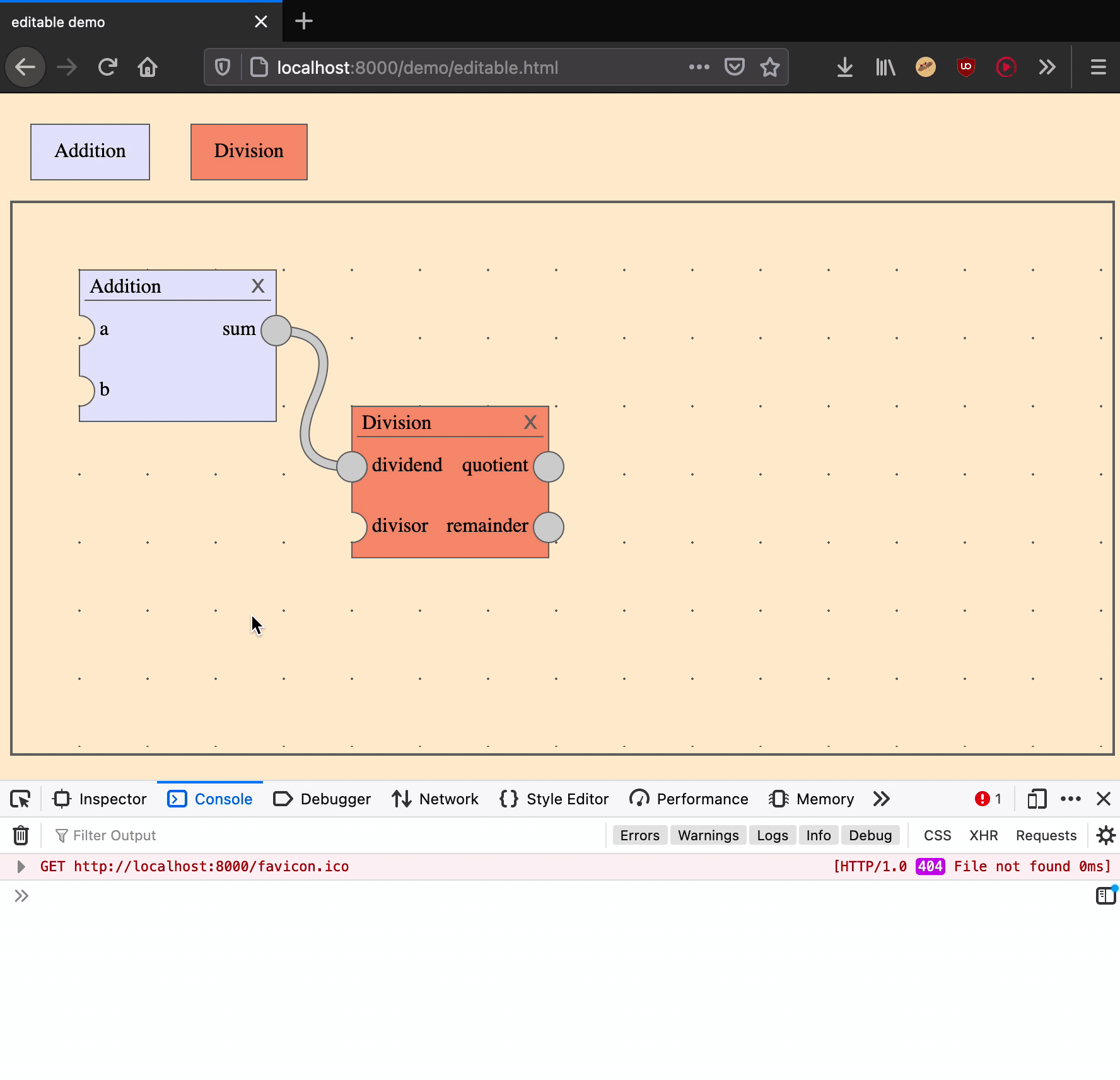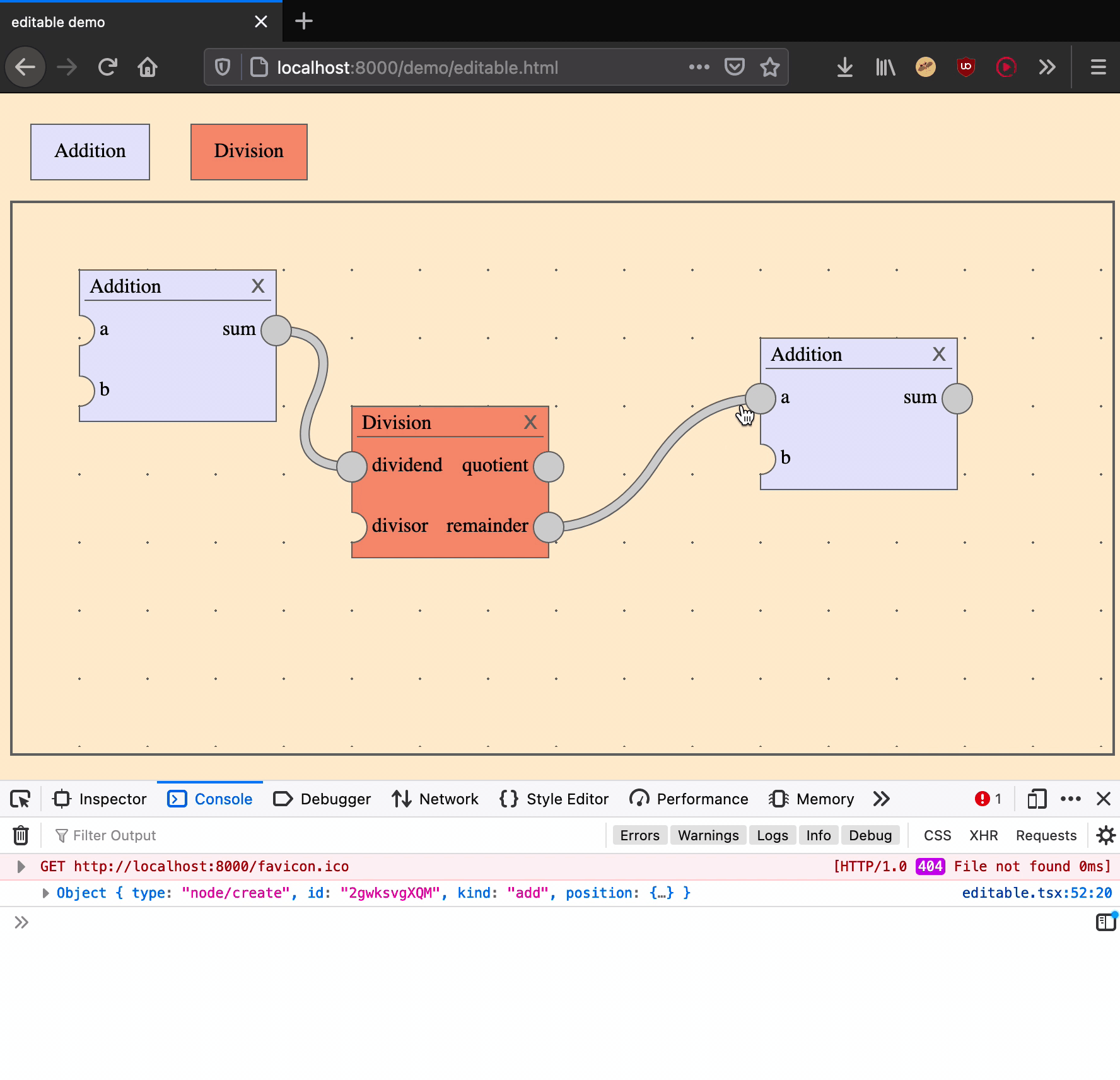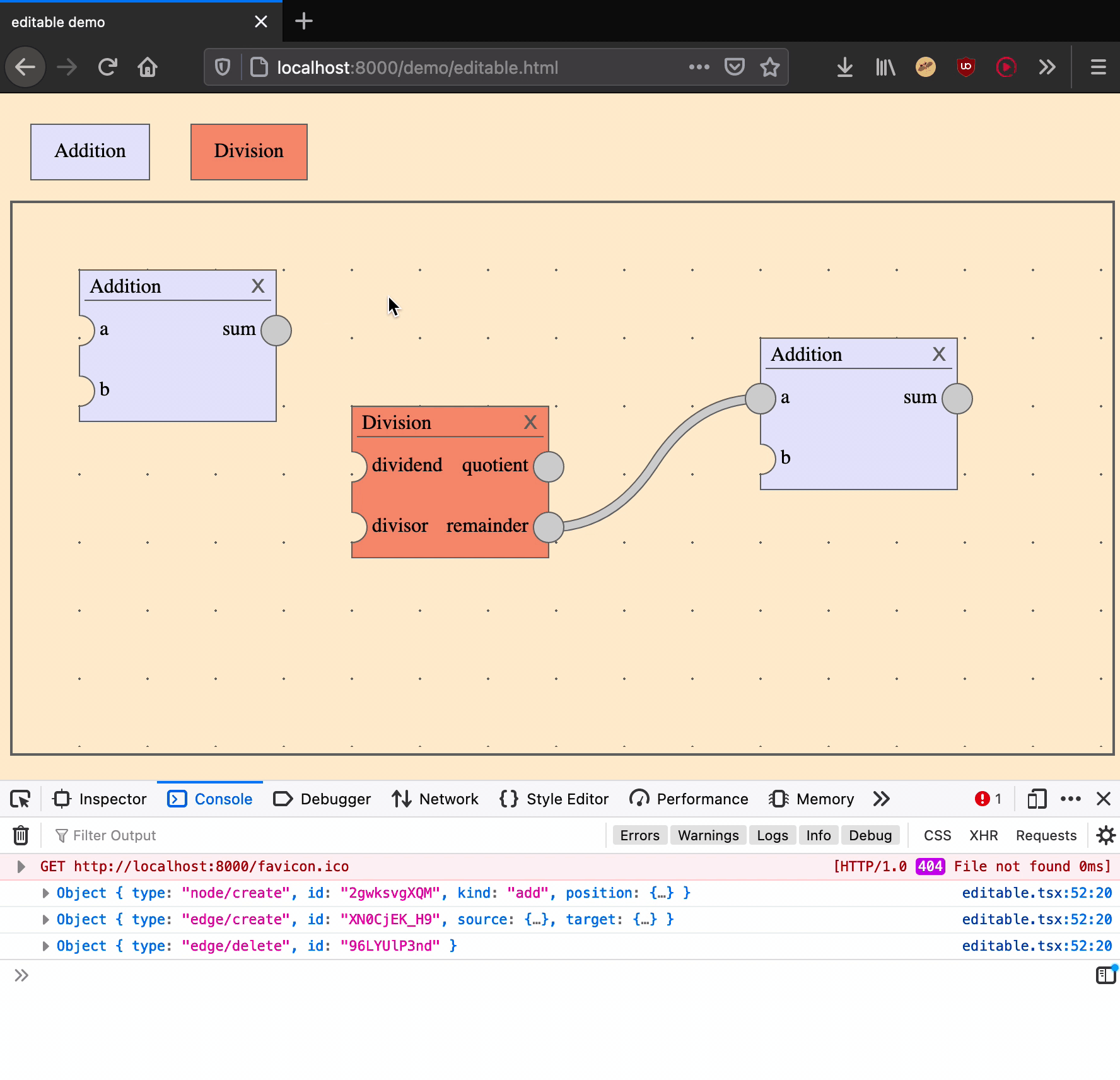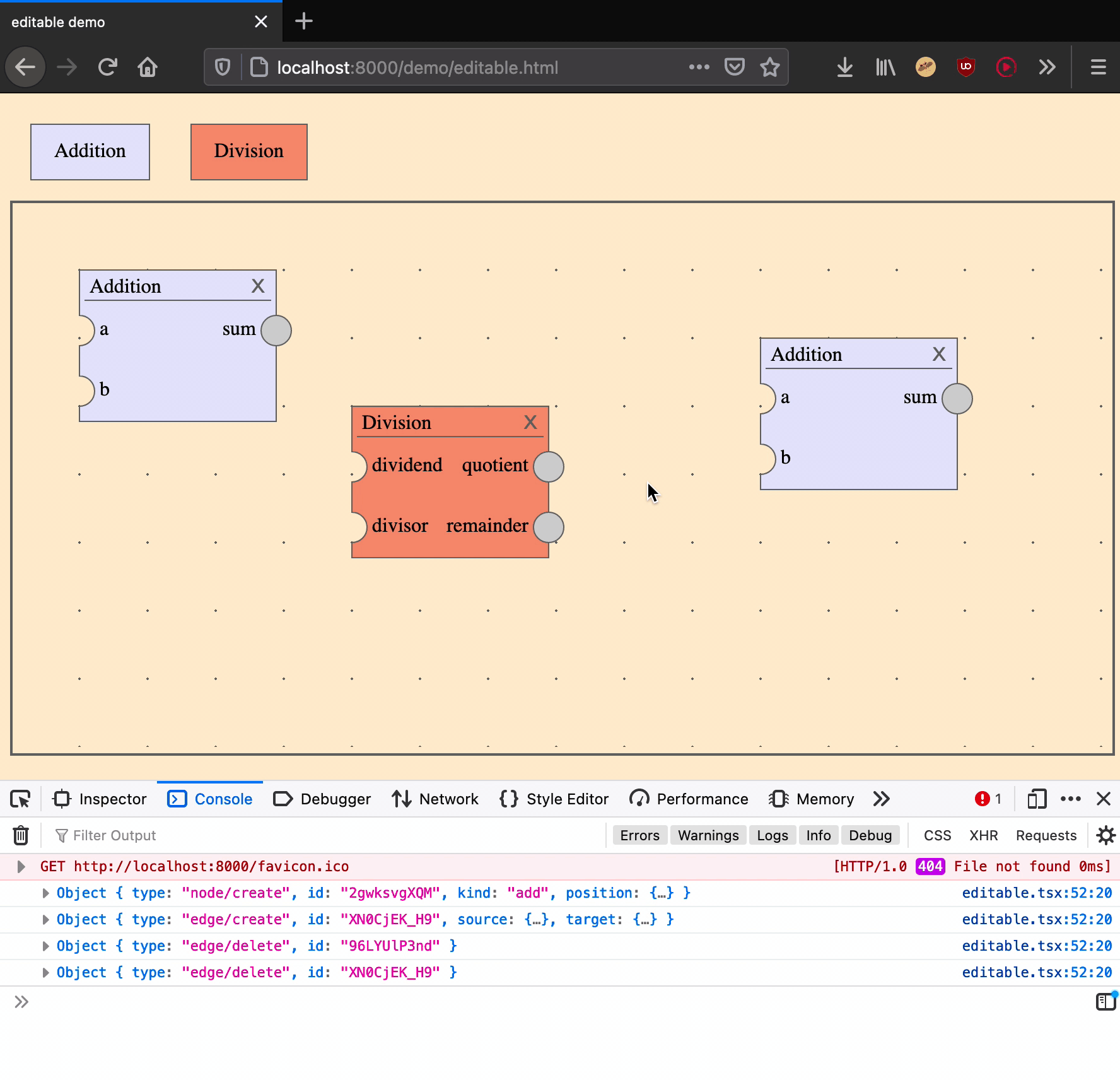
delete an edge
Move an edge
Moving an edge is an action that takes two arguments: an edge ID and the input port of a new target.
|
|
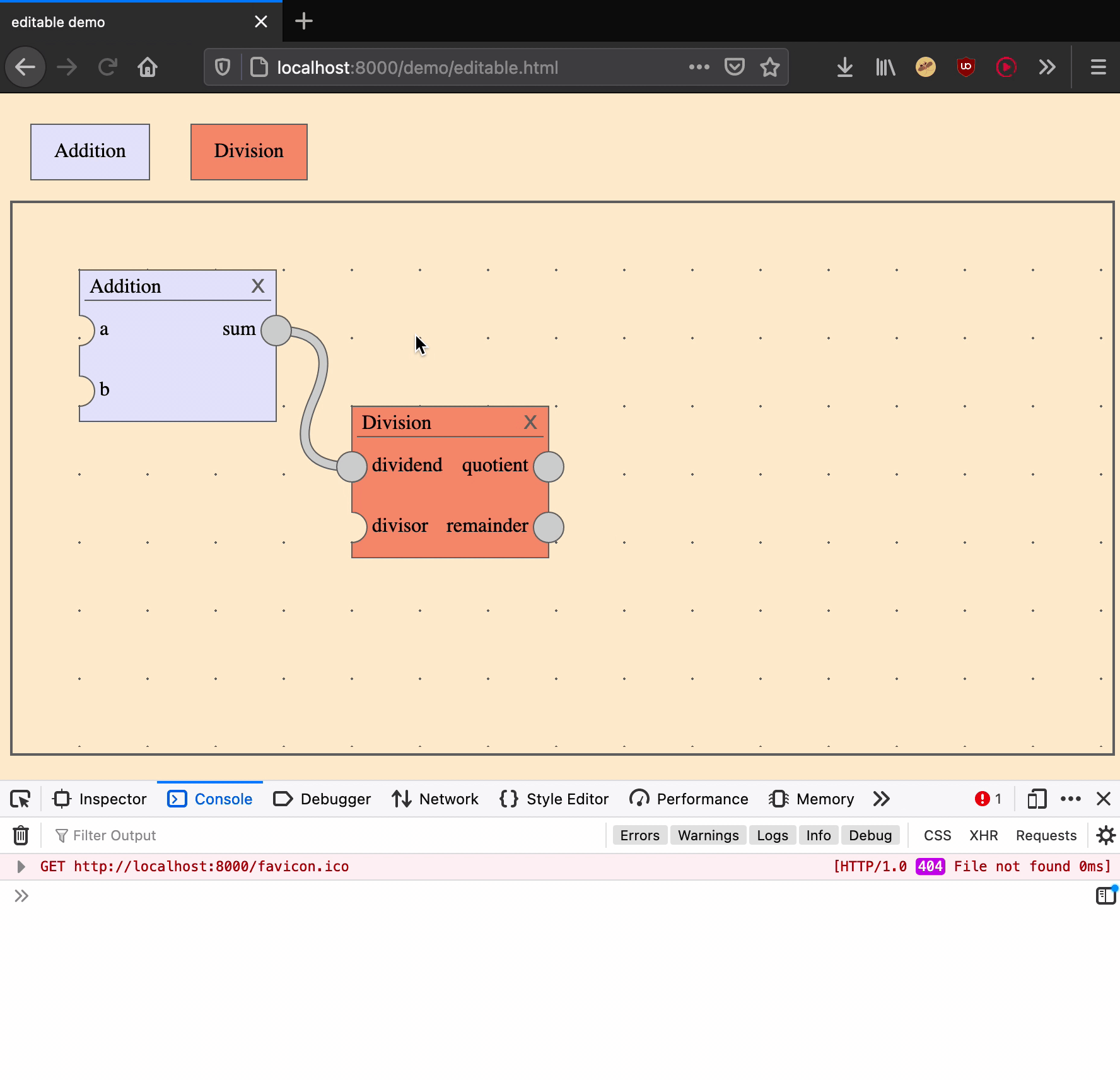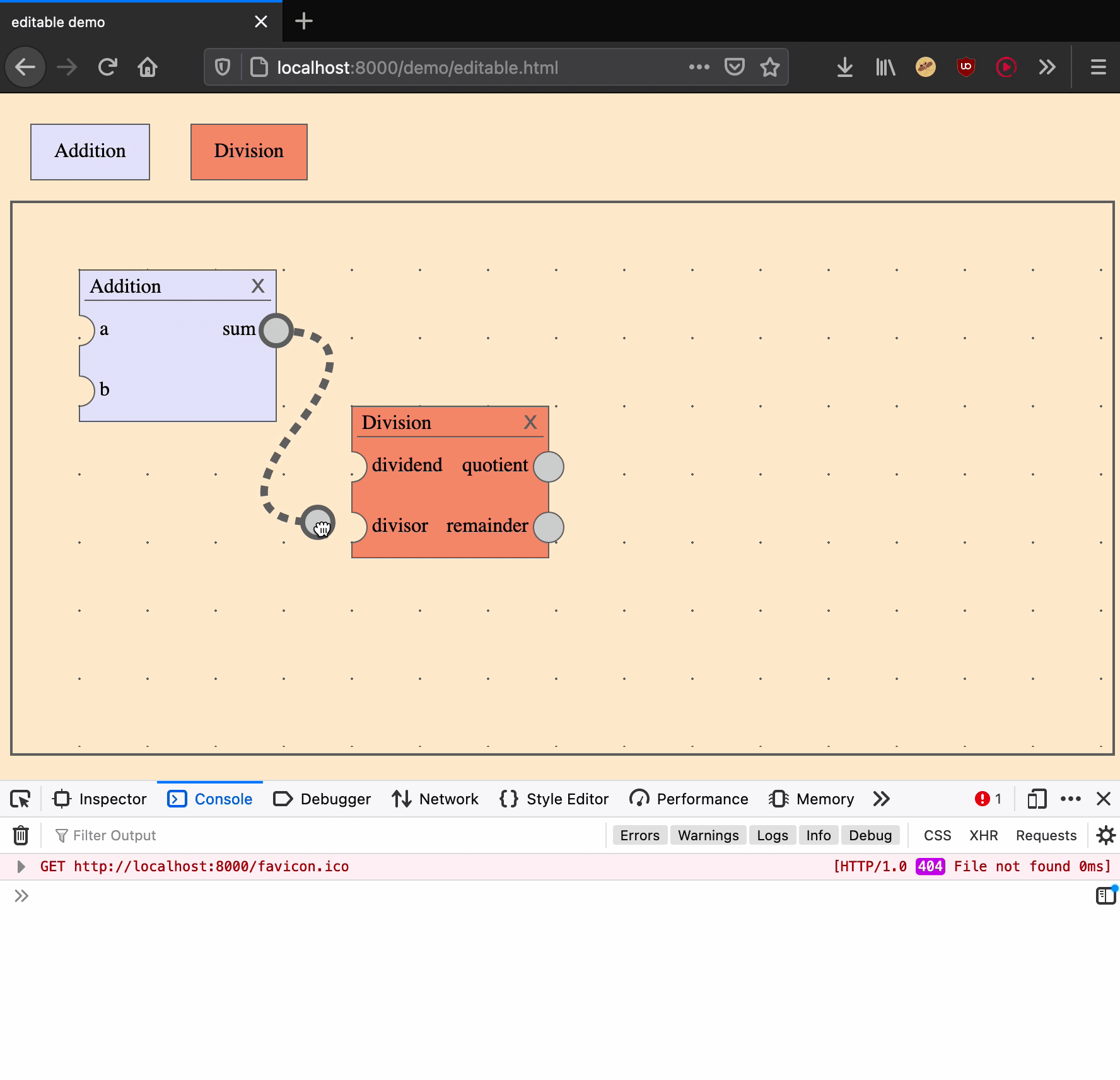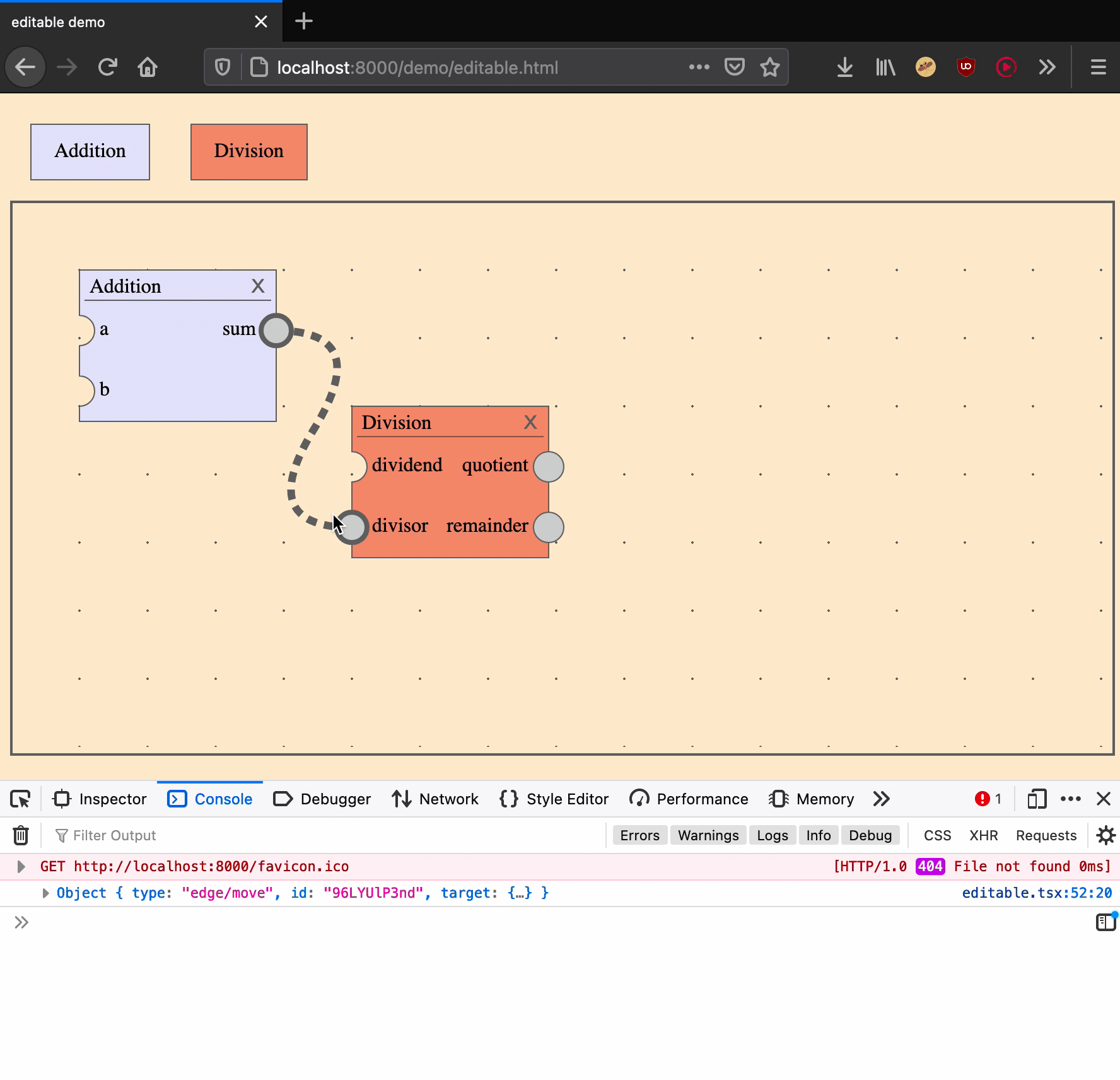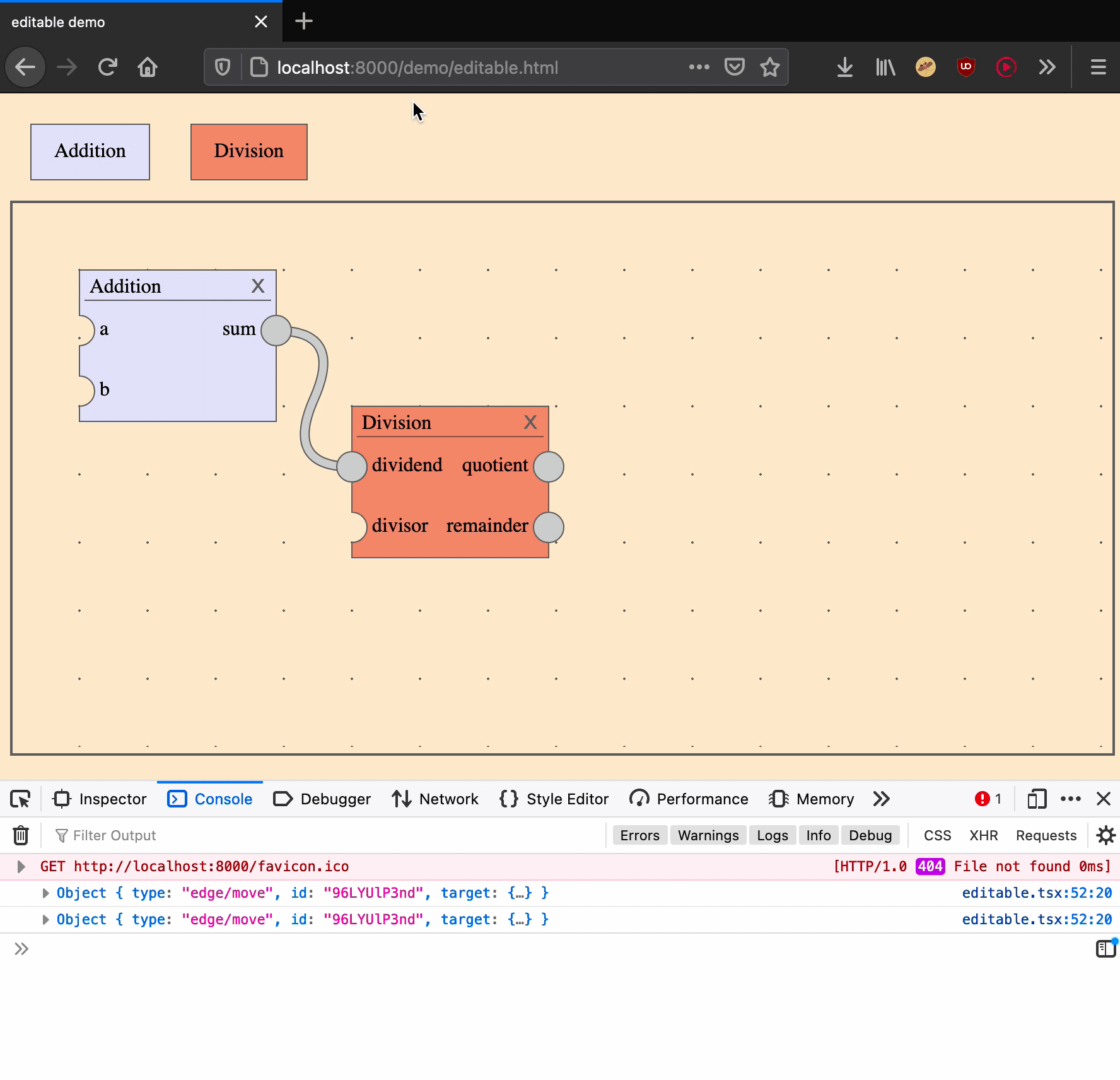
move an edge
Reduction
Implementing the reduce function we mentioned…
declare function reduce<S extends Schema>(
kinds: Kinds<S>,
state: EditorState<S>,
action: EditorAction<S>,
): EditorState<S>
… is fairly straightforward. We won’t include it inline, but you can read the source here.
The only tricky parts of applying our actions is making sure that the two representations of the graph structure – the values in state.edges and each Node.inputs and Node.outputs – stay in sync. For example, when we delete a node, we need to delete all of the edges from EditorState.edges that were connected to it, and we need to remove each of those edges from the input or output objects of the nodes on the other side.
Summary
Our broader goal in writing this up was to illustrate some higher-level TypeScript features and type-driven design patterns in the practical context of modern web development.
TypeScript is rapidly gaining serious traction in the web ecosystem, but the idea of types (and especially advanced features like generics) still provokes a lot of deserved skepticism: “Does this really help me? Is this just bikeshedding? How do I know when I need this? Why should I prioritize purity over practicality?” There are plenty of cases where over-engineering the types of an application has cost more energy than it saved, and careless type-level programming can easily spiral into a tangled illegible mess.
But these features, even the crazy ones, can be used in deliberate, principled ways to create amazing developer experiences. The idioms for safe type-level programming are very new and will keep evolving, but will become more solid the more we all iterate and share our results.
You can play with a live demo of the complete editor, install it from NPM, or visit the GitHub repo to see more usage examples.