Today we’re excited to share the story of how we decided to explore compression for libp2p streams and ended up achieving up to a 75% decrease in bandwidth use when performing an IPFS file exchange. This work is part of a broader initiative to drive speed-ups in file-sharing within IPFS – and P2P networks more generally – led by ResNetLab.
A few months ago, we challenged ourselves with a new project whose main objective is to design, prototype, measure, and evaluate ways of making file-transfers in P2P networks as fast as or even faster than a file exchange using a raw TCP protocol and a point-to-point connection (hint: by benefiting from streaming from multiple endpoints). After a thorough analysis of the state of the art, we’ve started designing several RFCs and implementing them with the goal of speeding up transfers at different levels of the IPFS stack. There are many ideas and prototypes in the pipeline, and today we share one that we are very excited about.
What we can learn from the most widely used protocol for file distribution today, HTTP
Compression is already an important and convenient way to increase performance in Web 2.0. For certain files, we can reach size reductions of up to 70%, with corresponding improvements in bandwidth requirements. Compression in the web happens at three different levels:
-
First, some file formats are compressed at the application level with specific optimized methods, such as specific video and image compression algorithms.
-
Then, general encryption can happen at the HTTP level (the resource transmitted is compressed end-to-end).
-
And finally, compression can be defined at the connection level, between two nodes of an HTTP connection.
To date, libp2p has not been using compression in any way in the exchange of files in IPFS, so why not mimic HTTP and use compression to drive speed-ups in IPFS file-exchange?
Drawing inspiration from Dropbox Broccoli
Another one of the great inspirations motivating us to explore compression is Dropbox. Dropbox syncs petabytes of data every day across millions of desktop clients, and they’ve recently released some of the work they’ve been doing around compression to reduce the latency and bandwidth requirements for clients when sending data to their backends. They reduce median latencies by more than 30% and the amount of data sent on the wire by the same amount. They reach this result by using a modified Brotli compression built in-house in Rust and code-named Broccoli (brot-cat-li) which compresses data at 3x the rate of Google’s Brotli implementation. They embed Broccoli in a Block sync protocol, which consists of two sub-protocols: one to sync file metadata, for example filename and size, and one to sync blocks, which are aligned chunks of up to 4 mebibyte (MiB) of a file. This first part, the metadata sync protocol, exposes an interface for the block sync engine to know which blocks are required to be uploaded or downloaded to complete the sync processes and arrive at a sync-complete state.
Dropbox’s work clearly stressed the impact compression may have in file-sharing systems, and the importance of exploring compression at an algorithmic level (using efficient compression algorithms) and at a protocol-level (embedding the algorithms within protocols which enable getting the most out of compression). After seeing the examples of first HTTP and now Dropbox, we definitely had to start exploring compression.
Evaluating how to integrate compression (Stream vs. Message) in Bitswap, the standard block exchange for IPFS
The data exchange subsystem currently used in IPFS is Bitswap, so we chose to start evaluating compression there. There are two relevant compression algorithms used within HTTP: gzip, the most common one, and br, the new challenger. Then, there are two main compression strategies used in HTTP: body compression, and the compression of headers using algorithms such as HPACK.
Following a similar approach, we implemented three different compression strategies in Bitswap to evaluate the one that achieved better performance improvements:
-
Block compression: Files within Bitswap are exchanged in the form of blocks. Files are composed of several blocks organized in a DAG structure with each block having a size limit of 256KB (check out these ProtoSchool tutorials to learn a bit more about this). In this compression approach, we compressed blocks before including them in a message and transmitting them through the link. This can be considered the equivalent to compressing the body in HTTP.
-
Full message compression: In this compression strategy instead of only compressing blocks we compressed every single message before sending it, i.e. the equivalent of compressing header+body in HTTP.
-
Stream compression: this method uses compression at a stream level, so every byte that enters the stream writer of a node at a transport level will be conveniently compressed using a stream wrapper. This is actually the approach that this Golang implementation of a Gzip HTTP handler follows.
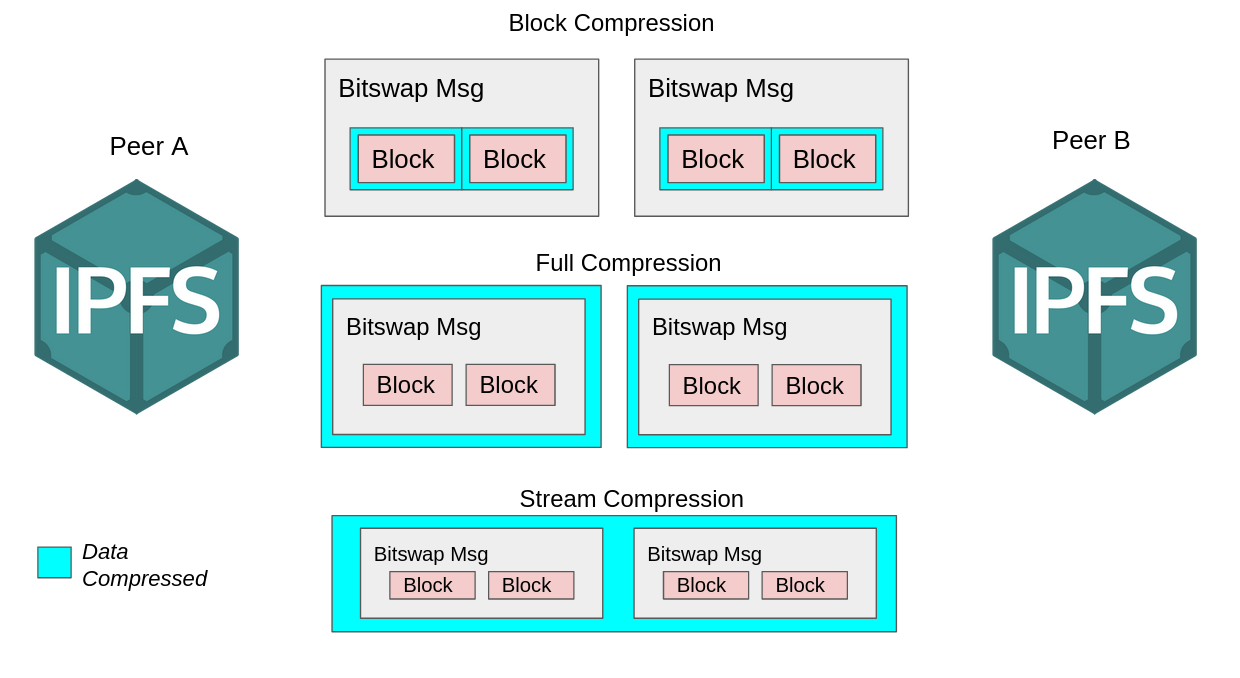
For convenience, we used Gzip as the compression algorithm for the aforementioned strategies. Many have reported the compression benefits of brotli over Gzip, but the lack of a stable implementation of brotli for Golang made us initially choose Gzip as the compression candidate for our prototypes.
We ran our evaluation plans on the implementations of the aforementioned strategies over our file-sharing Testground testbed reaching the following interesting results:
-
The rate of compression achieved using the block compression strategy is significantly lower than using the full message strategy or the stream compression. This is especially the case if we exchange random files, i.e. without a lot of redundancy. This made perfect sense, even when exchanging random files: the compressor is able to find redundant structures when compressing full messages (or the stream), while blocks of a random file normally present no redundancy at all.
-
The computational overhead and the file-sharing latency using block and full message compression is significantly higher than when using stream compression. This was another expected outcome: while in stream compression the node can directly “spit” the data to the transport layer because it is compressed “on-the-fly” through the stream wrapper, in the block and full message compression strategies the node has to perform the appropriate compressions before it can send the first byte to the transport layer.
Lessons learned from the evaluation of these implementations? Applying compression at a stream level can lead to significant performance improvements and a more efficient use of bandwidth compared to other compression strategies in P2P networking protocols. In some cases, and depending on factors such as the compression algorithm and the file format, the bandwidth savings can reach up to 50%! And this is how our compression RFC landed in libp2p.
Landing the prototype in libp2p
The compression strategy that led to the best results in our first prototypes of compression wasn’t at a protocol level but at a transport level. This meant that if we implemented compression embedded in the underlying transport layer, not only could file-sharing protocols benefit from compression, but potentially any other P2P protocol leveraging that same transport layer.
Bitswap uses libp2p as its underlying P2P transport, and just like Bitswap, there are already many applications and protocols using libp2p as their transport layer which could start directly benefiting from the use of compression without any changes to their protocols and applications (there are implementations of libp2p in Go, JavaScript, Rust, Python, JVM, C++, and even Nim).
This is how we ended up adding a new compression layer to the libp2p stack. We’ve implemented compression as a new transport upgrader between the stream multiplexer and the security layer. Thus, instead of individually compressing streams for each protocol (as we were doing in our Bitswap stream strategy), all the data coming from the multiplexer is conveniently compressed, encrypted at the security layer, and then sent through the underlying transport.
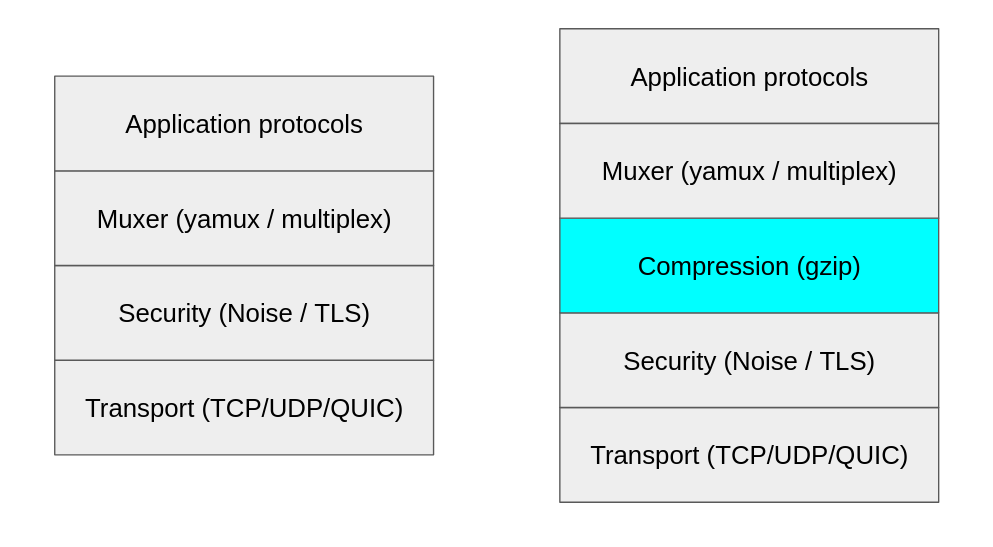
So why place compression there? The data stream received from the multiplexer will potentially show greater potential for compression than individual protocol streams, or the output of the security channel, so this is the reason for our placement decision.
The fact that compression has been implemented as a transport upgrader leads to it not being a breaking change in any way. The same way libp2p nodes currently negotiate the security protocol to use in their connection and fall back to a security protocol supported by both, or the use of an unencrypted connection, the same happens with compression. Libp2p nodes will negotiate the compression algorithm to use and if one of them doesn’t support compression, they simply fall back to an uncompressed connection.
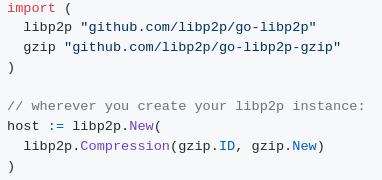
Consequently, the upgrade of applications to the use of compressed connections can be seamless; it simply requires an upgrade of the underlying libp2p node, adding this elegant line of code:
This preliminary compression implementation hasn’t landed yet on the go-libp2p upstream; it currently lives in a set of forked repos we’ve been using to test our implementation. But if you want to start using compression in libp2p right away, have a look at the following repo which guides you through a set of examples using compression, and points to all the forked versions you need to link to start using compression in your application: https://github.com/adlrocha/go-libp2p-compression-examples
Performance improvements
So what kind of improvements can we expect from the use of compression? Let’s start discussing the bandwidth savings that the use of compression can bring. For this test we exchanged datasets from these “awesome IPFS” datasets with compression enabled and disabled, and measured the nodes’ total use of bandwidth. We use the DefaultCompression level configuration for the underlying gzip algorithm in all our experiments.
|
Dataset |
Bandwidth use without compression |
Bandwidth use with compression |
Savings |
|
Size: 500MB |
509.667 MB |
230.83 MB |
54.71% |
|
World Wide Web History Project Size: 92MB |
100.512 MB |
52.677 MB |
47.59% |
|
Size: 196MB |
200.709 MB |
177.473 MB |
11.58% |
|
Size: 1.6GB |
1658.862 MB |
836.012 MB |
49.6% |
|
Size: 17GB |
17.82 GB |
4.33 GB |
75.7 % |
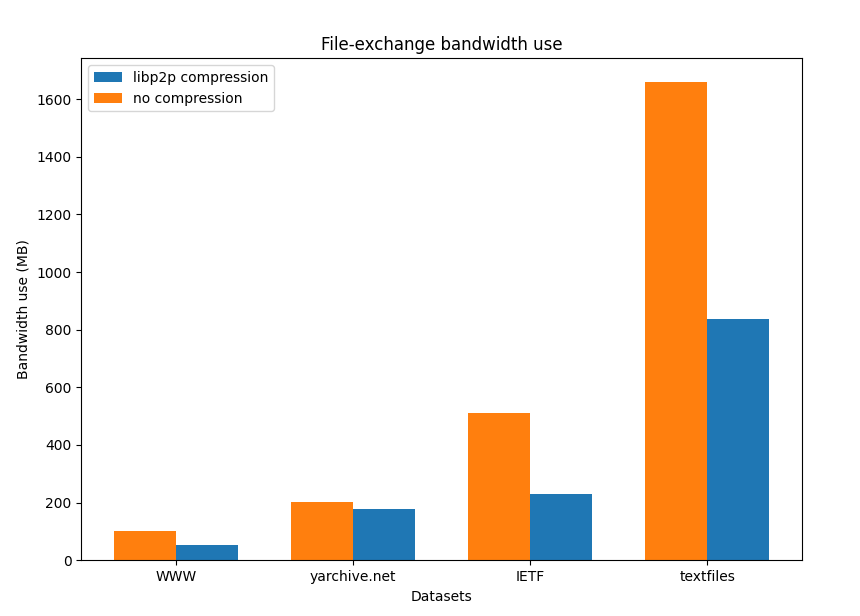
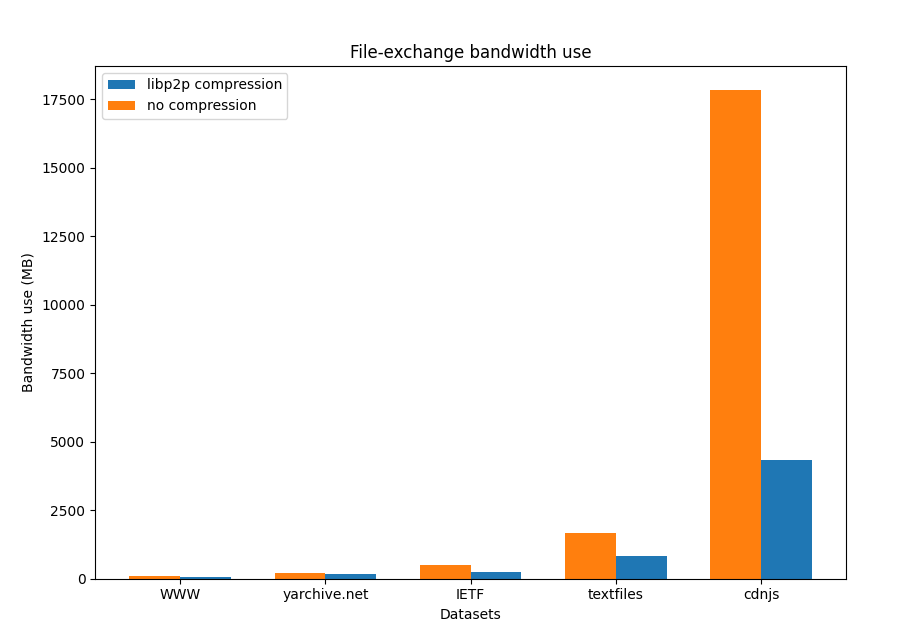
We can see that, depending on the dataset, we can achieve savings of up to 75% of the required bandwidth. From our tests we draw two interesting conclusions:
-
Large datasets benefit more from the use of compression due to the higher probability of finding redundancies in the data.
-
The compressor and the nature of the underlying data exchanged matters in the compression rate achieved and consequently the potential bandwidth savings that can be leveraged. Gzip performs very well with text-based data, but presents a pretty bad behavior when compressing images. So compression can generally achieve bandwidth savings as long as the right compression algorithm is used for the data exchanged.
What do these bandwidth savings mean for the time to fetch a full dataset from IPFS? We selected a few datasets from the aforementioned list that showed bandwidth savings, and ran the same file-exchange over Testground emulating different bandwidth and latency configurations for the links between the nodes (taking as a reference the average connection speed for different countries). The results are shown in the following table:
|
Average Connection Speed |
Time to fetch without compression |
Time to fetch with compression |
Latency Improvement |
|
IETF RFC Archive |
1339.47 s |
1338.46 s |
0.07% |
|
IETF RFC Archive Size: 500MB
|
1370.5 s |
1364.80 s |
0.4% |
|
World Wide Web History Project Size: 92MB
|
1100.76 s |
1100.99 s |
0.02% |
|
World Wide Web History Project Size: 92MB
|
1098.87 s |
1092.39 s |
0.5% |
|
Textfiles.com |
15489.85 s |
15334.95 s |
0.1% |
|
Textfiles.com Size: 1.6GB
|
15528.32 s |
15556.76 s |
0.18% |
Considering the results obtained from the bandwidth savings and comparing the time-to-fetch with compression and without compression leads to a bit of disappointment. Compression starts showing appreciable improvements for large datasets, but they can still be considered negligible (below the 1%). What this means for IPFS users is that a user in Portugal would only save half a minute in the download of the textfiles.com dataset (1658MBs) through IPFS when using compression, out of a total of almost 4.5hrs when transferring uncompressed data. We believe we can achieve better results by continuing to fine-tune the compression levels. Furthermore, compression is cumulative: the more data transferred, the greater the opportunity for compression – your daily usage will likely show even more interesting results.
The compression algorithm implementation we used for our transport was Golang’s standard implementation (compress/gzip). In light of the above results, we began to wonder if the Gzip implementation we were using was not efficient enough for our use case, so all the time gained from bandwidth savings was being lost in the compression process. We then decided to implement our gzip transport with a reportedly more efficient golang implementation of gzip and a brand new go-libp2p brotli compressed transport, and compared the computational overhead and bandwidth savings of the two implementations:
|
Dataset |
compress/ |
klauspost/ |
Brotli C impl |
Improvement |
Improvement |
|
IETF RFC Archive |
B: 230.83MB |
B: 248.11MB |
B: 167.58MB |
B: -7.8% |
B: 27.4% |
|
Textfiles.com |
B: 836.012MB |
B: 948.79MB |
B: 593.79MB |
B: -13% |
B: 28.97% |
The results of the experiment show how using an alternative implementation of the Gzip algorithm can lead to slightly worse bandwidth savings, but a significant improvement in the computational overhead of compression. Even more, we see how using an alternative (and reportedly better) compression algorithm results in achieving improvements in terms of bandwidth savings and time to compress. This demonstates the importance of choosing the right compressor for the task according to the metric that needs to be improved.
Conclusions
From the implementation of compression in libp2p we have gained a set of interesting insights. We’ve seen how compression can lead to significant bandwidth improvements for file-sharing and potentially many other protocols built over libp2p. The value of these bandwidth savings has to be considered in the overall framework under which Bitswap operates, that is in P2P networks. In these networks, users “donate” their bandwidth resources to serve content to other users. That said, any contribution towards avoiding upload bandwidth saturation is of significant value. Our results have shown that even moderate file exchanges of ~1GB, which is quite common for modern applications, can be shrunk by ~50% - a significant reduction!
However, these bandwidth savings don’t come for free. The use of compression adds a computational overhead that in some cases may end up removing all the savings achieved by reducing the amount of data exchanged. Furthermore, the underlying data exchanged can dramatically affect the compression performance (even leading to higher bandwidth and worse performance).
Show me the demo!
Future Work & invitation to join the research
As shown in our experiments, it is of the utmost importance to select the compression algorithm to be used wisely, according to the metric that needs to be optimized and the type of data to be exchanged. Different implementations of the same compression algorithm can lead to significant differences in terms of performance and compression rates.
From here, there are a number of lines for future work and ways in which you can contribute and build upon this work:
-
Explore the use of more efficient compression algorithms. As shown above, Golang’s standard implementation of Gzip is not the most computationally efficient in the wild, and this explains the high differences between the bandwidth saving results and the actual time-to-fetch improvements obtained in the tests. A simple next step to improve this would be to test other compression approaches like using Huffman tables (instead of full gzip) to minimize the computational overhead but achieve some bandwidth savings; or testing more complex compression algorithm and protocols such as the approach followed by Dropbox with Broccoli (we’ve already started exploring this approach with a new transport, do not hesitate to join our efforts).
-
Fine-tune the compression algorithms. Throughout all of our tests we have been using Gzip with the DefaultCompression Level and Brotli with an automatic window and a quality level of 2. A further exploration of the best configuration for these algorithms could achieve the right trade-off between computational overhead and compression rate to achieve even further improvements (have a look at this reference to start exploring this). Even more, we could devise a dynamic configuration of these algorithms according to the application and the data exchanged.
-
Explore the implementation of a negotiation protocol to allow libp2p nodes to agree on the compression to use according (at a stream level or transport level) to the data to be exchanged and the overlying protocol. This way according to the exchange of data to be performed by the application it can select the right compression algorithm to use with the other end and at what level (as long as both of them support it).
And probably many other things that we may be missing and that you can come up with! If you want to contribute to this work, you can start implementing your own compression transport for libp2p to see if you are able to reach further improvements in bandwidth savings and times-to-fetch (which let me tell you, considering the current gzip implementation you must definitely be able to do so). Adding a new compression algorithm to libp2p is easy: you just need to implement the libp2p compression interface and wrap the reader and writer of the libp2p connection into the compression’s algorithm interfaces. Read the code of the gzip and brotli transport implementations to see how simple it would be to add your own compression to libp2p. You can also check out and contribute to the work-in-progress transport implementation for broccoli. You can test your implementation over our Testground testbed, injecting your compression algorithm into the IPFS nodes and profiling the links between nodes.
Do not hesitate to reach out or open an issue to join our quest of driving speed-ups to file-sharing in P2P networks.
Until the next one, we bid you a great day!