A resilient system or network is fundamentally uncompromised by an isolated failure or network split. The system is malleable, adaptable to different conditions and capable of evolving to meet new requirements over time. That said, resilience here identifies also as a characteristic against changing system or network conditions, i.e., the system’s core operating principles adjust so that performance remains when the system scales up to serve increasing demand from more users. Building resilience into foundational infrastructure is the key in building a computing and networking fabric for human knowledge.
Mission & Vision
The mission of the Resilient Networks Lab is to build resilient distributed systems, by creating and operating a platform where researchers can collaborate openly and asynchronously on deep technical work.
Motivation & Description
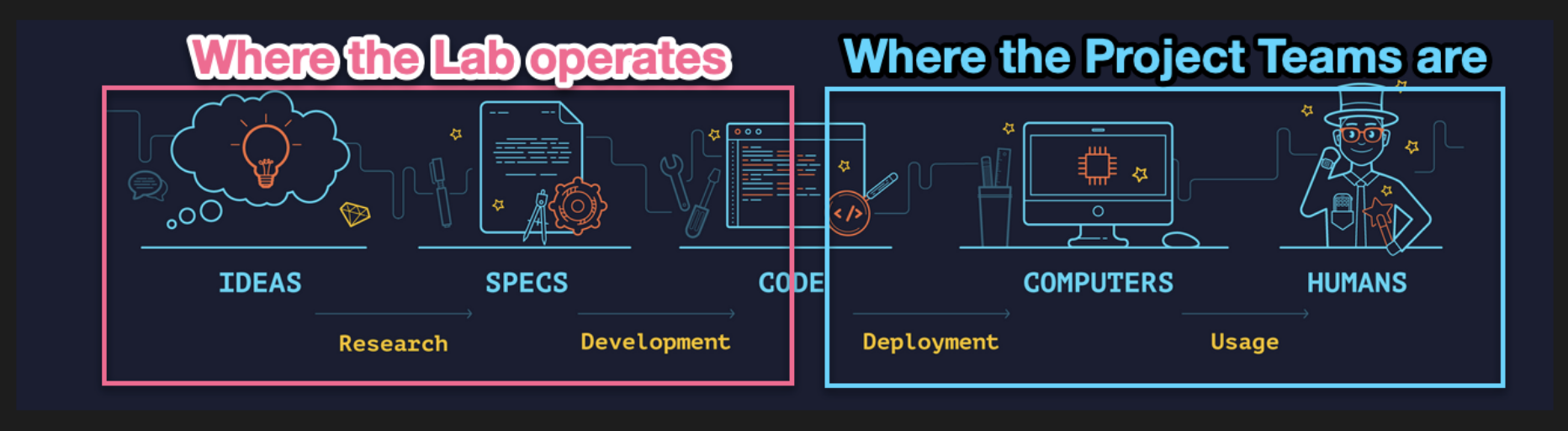
The lab’s genesis comes from a need present in the IPFS and libp2p projects to amp their research efforts to tackle the critical challenges of scaling up networks to planet scale and beyond. The Lab is designed to take ownership of the earlier stages on the research pipeline, from ideas to specs and to code.
Research Endeavours
- Decentralized Data Delivery Markets (3DMs): With the emergence of Decentralized Storage Networks and the rapid decrease in the price of storage services and hardware, there is a rapidly growing need to leverage the additional storage capacity contributed to Decentralized Storage Networks by new players, including end-users, and use it to deliver reliable and high-quality storage and delivery services. Similarly to Content Delivery Networks (CDNs) for the traditional Cloud Storage market, we now have the opportunity to build Decentralised CDNs for Decentralised Storage Networks. The Decentralized Data Delivery Markets (3DMs) Open Problem covers all the essential areas of work that need to be studied in order to create a fully permissionless free market for data delivery that supports fair data exchange on the service provided.
- Networking in Heterogeneous Runtimes: Edge computing has emerged as a distributed computing paradigm to overcome practical scalability limits of cloud computing. The main principle of edge computing is to leverage computational resources outside of the cloud to perform computations closer to data sources, avoiding unnecessary data transfers to the cloud and enabling faster responses for clients. Given the enormous amount of data that is expected to be produced at the edge of the network (by end-user devices), the edge-computing principle builds on the fact that “it is cheaper to bring computation to data, rather than data to computation.”
- Preserve users’ privacy when providing and fetching content: How to ensure that the user’s of the IPFS network can collect and provide information while mainting their full anonymity.
- Mutable data (naming, real-time, guarantees): Enabling a multitude of different patterns of interactions between users, machines and both. In other words, what are the essential primitives that must be provided for dynamic applications to exist, what are the guarantees they require (consistency, availability, persistence, authenticity, etc) from the underlying layer in order create powerful and complete applications in the Distributed Web.
- Human-readable naming: You can only have two of three properties for a name: human-meaningful, secure, decentralized. This is Zooko’s Trilemma. Can we have all 3, or even more? Can context related to some data help solve this problem?
- Enhanced bitswap/graphsync with more network smarts: Bitswap is a simple protocol and it generally works. However, we feel that its performance can be substantially improved. One of the main factors that hold performance back is the fact that a node cannot request a subgraph of the DAG and results in many round-trips in order to “walk down” the DAG. The current operation of bitswap is also very often linked to duplicate transmission and receipt of content which overloads both the end nodes and the network.
- Routing at scale (1M, 10M, 100M, 1B.. nodes): Content-addressable networks face the challenge of routing scalability, as the amount of addressable elements in the network rises by several orders of magnitude compared to the host-addressable Internet of today.
- PubSub at scale (1M, 10M, 100M, 1B.. nodes): As the IPFS system is evolving and growing, communicating new entries to the IPNS is becoming an issue due to the increased network and node load requirements. The expected growth of the system to multiple millions of nodes is going to create significant performance issues, which might render the system unusable. Despite the significant amount of related literature on the topic of pub/sub, very few systems have been tested to that level of scalability, while those that have been are mostly cloud-based, managed and structured infrastructures.
- Improved layouts to represent data in hash-linked graphs (using IPLD): IPFS offers a unique way to represent any kind of data in a hash-linked graph. What this means is that a file can be chunked in different ways and these chunks can be organized with the goal of improving file seek times, file fetching, reducing time to first byte and more, which creates the room for drastic improvements in the performance of certain applications (e.g. video streaming) and the memory footprint of each dataset. We believe this to be an evergreen field as the IPFS network improves and gets smarter, new ways to chunk and organize data will emerge for all sorts of usecases.

